










Theory of Automata
The theory of automata is the study of abstract machines and computational problems. The computation problems can be solved using these abstract machines. The abstract machine is called the automata or automaton.
Different names of Automata Theory are
- Theory of computation (TOC)
- Automata Theory
- Theory of Formal Languages and Computation
- Formal languages, Automata, Grammars
Here are the most important key terminologies explained in simple and clear wording
1. Alphabet (Σ) and Symbol in Automata Theory
An alphabet denoted as “Σ” (also called sigma) is a nonempty finite set of symbols. The elements of the alphabet are called symbols. A symbol is a single element (atomic entity) of Length 1.
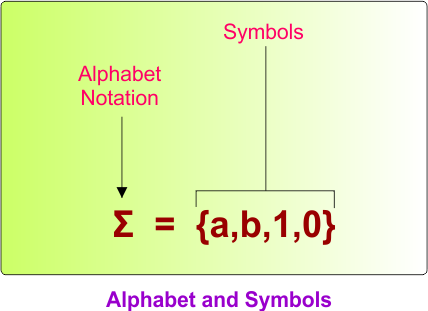
Alphabet (Σ) in Automata
An alphabet (Σ) is a finite, non-empty set of symbols. Alphabets are classified based on the number of symbols they contain. Classifications are given below
-
Unary Alphabet (|Σ| = 1) : Alphabet containing one symbol.
- Example: Σ = {a}
-
Binary Alphabet (|Σ| = 2): Alphabet containing two symbols.
-
Example: Σ = {0,1}
-
-
Ternary Alphabet (|Σ| = 3): Alphabet containing three symbols.
- Example: Σ = {a,b,c}
-
Quaternary Alphabet (|Σ| = 4): Alphabet containing four symbols.
- Example: Σ = {a,b,c,d}
-
k-ary Alphabet (|Σ| = k): Alphabet containing k symbols.
-
Example: Σ = {a₁, a₂, … , aₖ}
-
Symbols in Automata
Symbols are special notations used to represent alphabets, strings, languages, and operations in automata theory. The symbols a, b, c, …, x, y, z and 0, 1, 2, …, 9 are basic symbols used to form strings. In general, any characters, digits, or special symbols can be used as alphabet symbols to construct strings in automata theory.
Examples of possible symbols:
- Lowercase letters: a, b, c, …, z
- Uppercase letters: A, B, C, …, Z
- Digits: 0, 1, 2, …, 9
- Special symbols: +, −, *, /, @, #, $, %
All such symbols can be elements of an alphabet Σ, and strings are formed by combining these symbols in sequence.
| Important:
Important Points
|
2. Strings in Automata Theory
A string (or word) is a finite sequence of symbols taken from an alphabet Σ.

Valid String Examples
A valid string must contain only symbols from the alphabet Σ.
- If Σ = {0,1}, then 0, 01, 1101, 11010,…so on, are valid strings.
- If Σ = {a,b}, then a, aaab, bbbba, ababba,…so on, are valid strings.
- If Σ = {0,1, 2,3,…..,9}, then 12345, 56654, 11455, 8888888,…so on, are valid strings.
- If Σ = {a,b,c,d,…,z}, then theory, beautiful, hello,…so on, are valid strings.
Invalid String Examples
A string is invalid if it contains symbols not present in the given alphabet Σ.
-
If Σ = {0,1}, then 012, 102, 2, 10a are invalid strings (because 2 and a are not in Σ).
-
If Σ = {a,b}, then abc, acb, a1b, cab are invalid strings (because c and 1 are not in Σ).
Order of symbols and repetition
In strings, both the order of symbols and the repetition of symbols matter.
-
Order Matters: Changing the sequence of symbols gives a different string.
-
Example: If Σ = {a, b} then “ab” ≠ “ba”
-
-
Repetition Matters: Repeating a symbol changes the string.
-
Example: If Σ = {a, b} then “a” ≠ “aa”
-
So, a string is defined by the exact sequence of symbols, including their order and how many times each appears.
Length of the String
The number of symbols in a string is called the length of the string.

- if w = 1011, then the length of the string (|w|) = 4.
- The string with no symbols is called the empty string. It is represented by ε (called epsilon). The length of an empty string is 0
Specific Length of strings over the alphabet (Σ)
If the alphabet size = k and string length = n, the number of strings of length n = kⁿ. Look at the following diagram

Example: Let the alphabet be Σ = {a, b}, which means we can form strings using only the symbols a and b.
- A string of length 0 is called the empty string and is written as ε.
- For length 1, the possible strings are: a, b.
- For length 2, the possible strings are: aa, ab, ba, bb.
- For length 3, the possible strings are: aaa, aab, aba, abb, baa, bab, bba, bbb.
- For length 4, the possible strings are: aaaa, aaab, aaba, aabb, abaa, abab, abba, abbb, baaa, baab, baba, babb, bbaa, bbab, bbba, bbbb.
In general, for alphabet size 2, the total number of strings of length n is 2ⁿ.
All possible strings over the alphabet (Σ)
The set of all possible strings that can be formed using symbols from an alphabet Σ is called Σ* (Kleene Star of Σ). It includes strings of every possible finite length, including the empty string ε.
Examples:
-
If Σ = {a}, then Σ* = {ε, a, aa, aaa, aaaa, …}
-
If Σ = {0,1}, then Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, …}
-
If Σ = {a,b,c}, then Σ* = {ε, a, b, c, aa, ab, ac, ba, bb, bc, ca, cb, cc, …}
Key Points:
-
Includes strings of length 0,1,2,3,…∞
-
The empty string ε is always included
-
The number of strings of length n over an alphabet of size k = kⁿ
-
Σ* contains all possible combinations of symbols in Σ.
Reversal of a String

The reversal of a string is obtained by writing the symbols of the string in the opposite order.
- Syntax: If w = a₁a₂a₃…aₙ, then the reversal of the string is written as wᴿ = aₙaₙ₋₁…a₂a₁.
- Example: If w = abc, then its reversal is wᴿ = cba.
Concatenation of Strings
Concatenation is the operation of joining two strings together to form a new string.
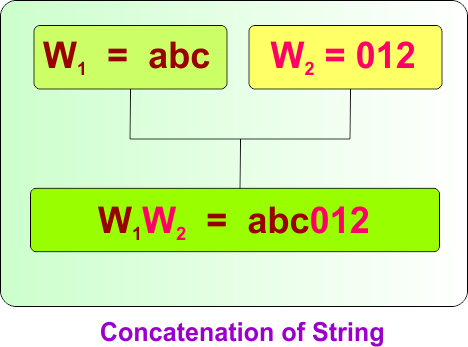
- Notation: If x and y are strings, their concatenation is written as xy.
- Example: If x = ab and y = ba, then xy = abba. Similarly If x = ab, y = ba, and z = mn, then zxy = mnabba.
- Length Rule: |xy| = |x| + |y| (the length of the new string is the sum of both lengths).
- Order Matters: xy ≠ yx in general.
- Example: Let x = ab and y = c
- xy = abc
- yx = cab
- Since abc ≠ cab, the order of strings matters in concatenation.
- Associative Property: (xy)z = x(yz).
- Identity Element: ε (epsilon) acts as the identity element for concatenation.
- Left Identity: εx = x.
- Right Identity: xε = x.
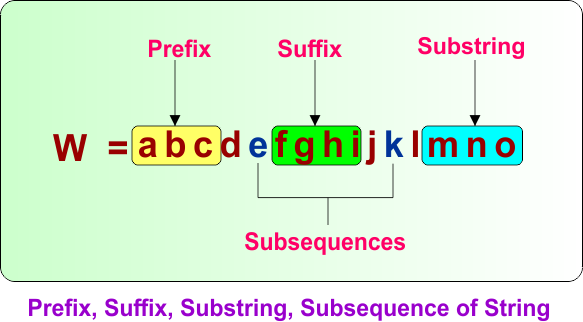
Prefix, Suffix, Substring, Subsequence of string
- A prefix of a string is any substring that starts from the first symbol of the string and may end at any position.
- A suffix of a string is any substring that ends at the last symbol of the string and may start at any position within the string.
- A substring of a string is a consecutive sequence of characters that appears anywhere inside the string.
- A subsequence of a string is formed by deleting zero or more symbols from the string without changing the order of the remaining symbols.
Note: If a symbol repeats, subsequences that differ only in the position of identical symbols are considered the same. The total number of distinct subsequences is less than 2ⁿ.
Look at the following diagram, which shows the examples of prefix, suffix, and substring in automata theory
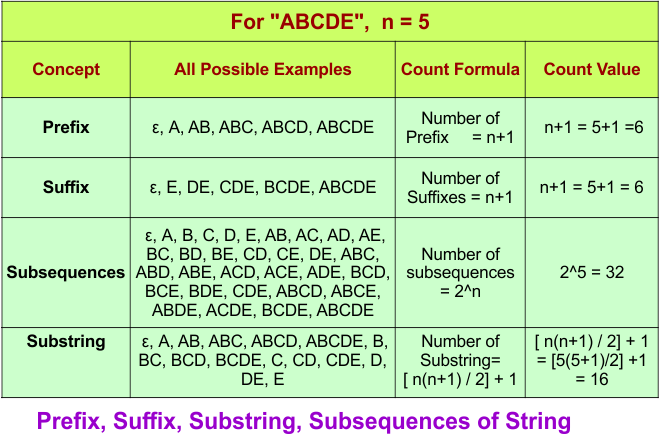
How to get Substring formula: n(n + 1) / 2
Let w = abcde (length n = 5). A substring is any continuous part of the string. To count them, we consider all possible starting positions.
- Starting at position 1 (a): a, ab, abc, abcd, abcde → 5 substrings
- Starting at position 2 (b): b, bc, bcd, bcde → 4 substrings
- Starting at position 3 (c): c, cd, cde → 3 substrings
- Starting at position 4 (d): d, de → 2 substrings
- Starting at position 5 (e): e → 1 substring
Adding them gives 5 + 4 + 3 + 2 + 1 = 15 substrings. In general, the number of substrings of a string of length n is n(n+1)/2, which matches this example: 5(5+1)/2 = 15. Adding 1 in the end represents the ε (epsilon) in the formula.
Note:
- Prefix, suffix, and substring always contain consecutive characters.
- Every prefix and suffix is a substring, but not every substring is a prefix or suffix.
- proper prefix, a proper suffix, and a proper substring do not contain ε (epsilon).
- Proper Prefix / Proper Suffix ⊆ Substring ⊆ Subsequence
Set of all strings over the given alphabet
The set of all strings over a given alphabet Σ is denoted by Σ* (called the Kleene Star of Σ). It includes all possible strings of any finite length, including the empty string ε.
Properties:
- Includes strings of length 0, 1, 2, 3, … infinitely.
- Concatenation of any number of symbols from Σ forms a string in Σ*.
The content of Σ* depends on the number of symbols in the alphabet. Following diagram shows all

Observation: For alphabet size k, number of strings of length n = kⁿ, and Σ* is the union of strings of all lengths 0,1,2,… infinitely. This shows how Σ* grows rapidly as the alphabet size increases.
Power of a String
If w = ab, then the power of the string means repeated concatenation of w with itself.
Example:
- w⁰ = ε
- w¹ = ab
- w² = abab
- w³ = ababab
- w⁴ = abababab
- In general, wⁿ means concatenating the string w with itself n times.
Palindrome String
A palindrome string is a string that reads the same forward and backward (i.e., w = wᴿ).
- Example: aba, aa, abba, madam, eye.
Set Vs String
Set: A collection of distinct elements where order does not matter, e.g., {a, b} = {b, a}.
String: An ordered sequence of symbols where order matters, e.g., “ab” ≠ “ba”.
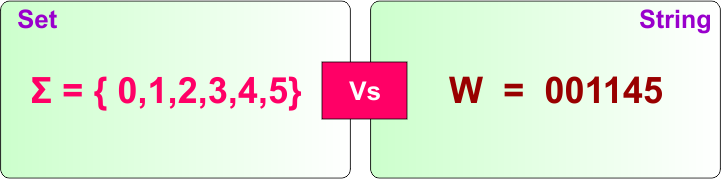
Here is a clear comparison table for Set vs String in TOC:
| Basis | Set | String |
|---|---|---|
| Definition | A collection of elements | A sequence of symbols |
| Order | Order does not matter, i.e., {a,b} = {b,a} | Order matters, i.e., ab is not equal to ba |
| Repetition | Duplicate elements not allowed | Symbols can repeat, i.e., aababbba |
| Written As | {a, b, c} | abc |
| Example | {a, b} | ab |
| Length | No concept of length, finite or infinite | Has length which is always finite |
| Empty Form | ∅ (empty set) | ε (empty string) |
| Used For | In TOC, set is used to represent alphabet symbols. | used as the input sequence of symbols taken from an alphabet Σ |
Exercise about strings in Automata
Question 1: Let Σ= {a}, How many Strings are there over Σ ?
Answer: If Σ = {a}, then there are infinitely many strings over Σ because we can form ε, a, aa, aaa, aaaa, and so on endlessly (since Σ* is infinite). For every length n ≥ 0, there is exactly one string (aⁿ), such as ε (length 0), a (length 1), aa (length 2), aaa (length 3), and so forth without end, but each string has finite length.
Question 02: Consider the strings over the alphabet {a,b,c}.
- How many strings of length 5 are there?
- How many strings of length n are there?
- How many strings of length 7 are there, in which the first, middle, and last symbols are b?
- How many strings of length at most 5 are there?
Answer:
- Each position has 3 choices. So, 35=243 strings is the answer
- Each of n positions has 3 choices. So, 3n
- Length = 7, Positions fixed are
-
-
1st = b
-
4th (middle) = b
-
7th = b
-
The remaining positions are 4, therefore each has 3 choices. So, 34 = 81 strings
- v. Length ≤ 5 means: 0, 1, 2, 3, 4, 5
- Total: 30+31+32+33+34+35 =1+3+9+27+81+243 364 strings
NOTE:
|
3. Language (L) in Automata Theory
Language: A language is a set of strings formed from an alphabet according to specific rules. Language is of two types in automata theory
-
Finite Language: Contains a limited number of strings, e.g., L = {a, ab, ba}.
-
Infinite Language: Contains infinitely many strings, e.g., L = {aⁿ | n ≥ 1}.
Finite languages are countable, while infinite languages grow without bound.
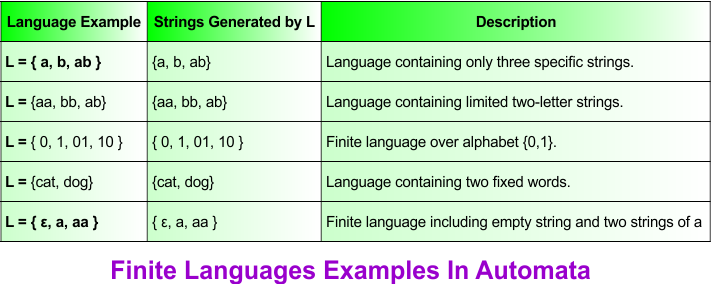
Examples of Language
Examples of finite languages are given in the following diagram
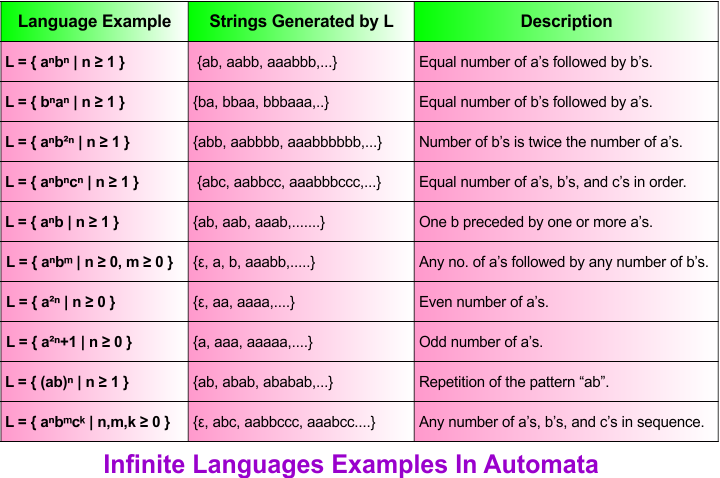
Examples of infinite languages are given in the following diagram
Here are some examples of languages over Σ given in the following diagram. Let’s take Σ = {a, b}. A language over Σ is any set of strings formed from Σ, including finite or infinite sets.

A language over Σ can be any subset of Σ* (L⊆Σ*), finite or infinite, empty, or the whole set.
Operations on Language
In Theory of Automata, a language is a set of strings over an alphabet Σ. Several operations can be performed on languages to create new languages. Here’s a concise explanation:
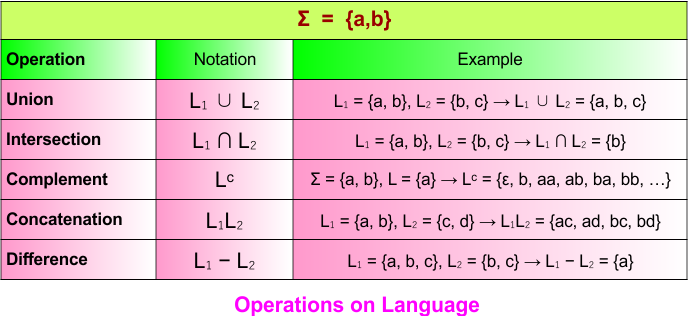
-
Union (L₁ ∪ L₂) → All strings that belong to L₁ or L₂ or both.
-
Example: L₁ = {a, b}, L₂ = {b, c} → L₁ ∪ L₂ = {a, b, c}
-
-
Intersection (L₁ ∩ L₂) → All strings that belong to both L₁ and L₂.
-
Example: L₁ = {a, b}, L₂ = {b, c} → L₁ ∩ L₂ = {b}
-
-
Complement (Lᶜ) → All strings in Σ* that are not in L.
-
Example: Σ = {a, b}, L = {a} → Lᶜ = {ε, b, aa, ab, ba, bb, …}
-
-
Concatenation (L₁L₂) → All strings formed by joining a string from L₁ with a string from L₂.
- Example: L₁ = {a, b}, L₂ = {c, d} → L₁L₂ = {ac, ad, bc, bd}
- Difference (L₁ − L₂) → All strings in L₁ that are not in L₂.
- Example: L₁ = {a, b, c}, L₂ = {b, c} → L₁ − L₂ = {a}
These operations allow constructing complex languages from simpler ones.
Reversal of a Language
The reversal of a language L, denoted Lᴿ, is the set of strings obtained by reversing every string in L.

Mathematical notation: LR ={wR ∣ w∈L}
Where wᴿ is the reversal of string w.
Example: Let L = {ab, aab, baa}
-
Reverse each string:
-
(ab)ᴿ = ba
-
(aab)ᴿ = baa
-
(baa)ᴿ = aab
-
-
So, Lᴿ = {ba, baa, aab}
Notes:
- Reversal preserves the number of strings but changes the order of symbols in each string.
- If L contains ε, then εᴿ = ε, so it remains in Lᴿ.
This operation is often used in NFA to DFA conversions and studying palindromes in languages.
|
After reversal of a language:
So it is not necessary that L=LR
|

Palindrome Language
A palindrome language L is a language in which every string reads the same forward and backward (i.e., w = wᴿ).
Mathematical notation: L = { w ∈ Σ* ∣ w = wR }
Example: Let Σ = {a, b}
-
L = {ε, a, b, aa, bb, aba, bab, abba, baab, …}
Here, each string is the same when reversed, so all are palindromes.
Power / Exponential of a Language
The power of a language is a concept in formal languages that describes repeated concatenation of strings from the language.

Where:
- L1
- , and so on.
Example 1:
Let L = {a, b}
- L¹ = {a, b}
- L² = {aa, ab, ba, bb}
- L³ = {aaa, aab, aba, abb, baa, bab, bba, bbb}
Example 2:
Let L = {ab}
- L² = {abab}
- L³ = {ababab}
Kleene Closure/Star of a Language
The Kleene Closure of a language L, written as L*, is the set of all strings formed by concatenating zero or more strings from L, including the empty string ε for L⁰.
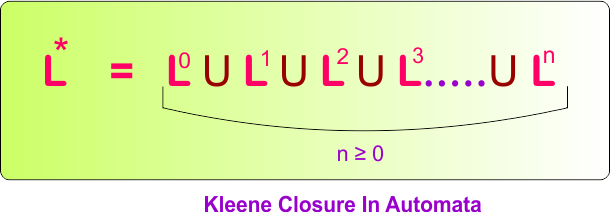
where:
- L⁰ = {ε} (empty string)
- L¹ = L
- L² = L · L (concatenation of L with L)
- so on…
- It continues for all n ≥ 0 (infinitely many times).
Example: 1
Example: If L = {a}
- L⁰ = {ε}
- L¹ = {a}
- L² = {aa}
- L³ = {aaa}
So, L* = {ε, a, aa, aaa, aaaa, …}.
Example: 2
If L = {ab, c}
- L⁰ = {ε}
- L¹ = {ab, c}
- L² = L.L= {abab, abc, cab, cc}
- L³ =L.L.L= {ababab, ababc, abcab, abcc, cabab, cabc, ccab, ccc}
So, L* = {ε, ab, c, abab, abc, cab, cc, ababab, ababc, abcab, …}.
Kleene Plus of a Language
The Kleene Plus of a language L, written as L⁺, is the set of all strings formed by concatenating one or more strings from L.

It does not include the empty string ε unless ε is already in L.
Example 1
If L = {a}
-
L¹ = {a}
-
L² = {aa}
-
L³ = {aaa}
So, L⁺ = {a, aa, aaa, aaaa, …}
Example 2
If L = {ab, c}
-
L¹ = {ab, c}
-
L² = {abab, abc, cab, cc}
So, L⁺ = {ab, c, abab, abc, cab, cc, …}
Important: Key Difference
|
Exercise of Language in automata
Question 1.
Let L be a language. If L = LR, then every string in L is a Palindrome ??
Solution:
No, not necessarily.
If L = Lᴿ, it means the language is closed under reversal, not that every string is a palindrome.
Condition: L=LR⇒For every w∈L, wR ∈ L
- Counter Example: Let L = {ab, ba}
- Reverse of ab = ba
- Reverse of ba = ab
So Lᴿ = {ba, ab} = L, but ab ≠ ba, therefore not every string is a palindrome.
Conclusion: If L = Lᴿ, the language contains reverses of its strings, but each string itself does not have to be a palindrome
Question 02:
Let L = {ab, aa, baa}. Which of the following strings are in L*: abaabaaabaa, aaaabaaaa, baaaaabaaaab, baaaaabaa? Which strings are in L4?
Solution:
4. Power / Exponential of Alphabet
The power (or exponential) of an alphabet Σ, written as Σⁿ, is the set of all strings of length n formed using the symbols of Σ.
- Σ⁰ = {ε} (string of length 0)
- Σ¹ = Σ (all strings of length 1)
- Σ² = all strings of length 2, and so on.
Example 1: If Σ = {a, b}
-
Σ⁰ = {ε}
-
Σ¹ = {a, b}
-
Σ² = {aa, ab, ba, bb}
-
Σ³ = {aaa, aab, aba, abb, baa, bab, bba, bbb}
-
Σ⁴ = all strings of length 4 over {a, b} (e.g., aaaa, aaab, aaba, …)
-
Σ⁵ = all strings of length 5 over {a, b} (e.g., aaaaa, aaaab, aaaba, …)
- so on…
Example 2: If Σ = {a, b, c}
-
Σ⁰ = {ε}
-
Σ¹ = {a, b, c}
-
Σ² = {aa, ab, ac, ba, bb, bc, ca, cb, cc}
-
Σ³ = {aaa, aab, aac, aba, abb, abc, aca, acb, acc, …}
- so on…
5. Kleene Star of the Alphabet vs Kleene Star of a Language
Kleene Star of an Alphabet (Σ*) means the set of all possible strings (including ε) formed using symbols of the alphabet Σ.
- Example: If Σ = {a, b}
- Σ* = {ε, a, b, aa, ab, ba, bb, aaa, aab, …}
Kleene Star of a Language (L*) means the set of all strings formed by concatenating strings from language L zero or more times.
- Example: If L = {ab, c}
- L* = {ε, ab, c, abab, abc, cab, cc, …}
Difference:
- Σ* uses individual symbols of an alphabet to form strings.
- L* uses complete strings from a language and concatenates them.
Exercise Questions
Question 01
Assume L is a language over alphabet Σ and ε denotes the empty string. Which of the following statements is/are always true?
- Σ* − {ε} = Σ⁺
- L* {ε} = L⁺
- Σ* = Σ⁺ ∪ {ε}
- L* = L* ∪ {ε}
Solution:
- Σ* − {ε} = Σ⁺ → True (Σ⁺ contains all strings of length ≥ 1).
- L* {ε} = L⁺ → False (since L*{ε} = L*, not L⁺).
- Σ* = Σ⁺ ∪ {ε} → True (Σ* includes all strings plus ε).
- L* = L* ∪ {ε} → True (ε is already in L*).
Correct statements are i, iii, and iv.
Question 02
Assume L is a language over alphabet Σ and ε denotes the empty string. Which of the following statements is/are always true?
- ε ∉ L⁺
- ε ∈ L*
- ε ∈ Σ*
- ε ∉ Σ⁺
Solution:
Check each statement:
-
ε ∉ L⁺ → True
L⁺ = L¹ ∪ L² ∪ … (one or more concatenations), so ε is not included unless ε is already in L. -
ε ∈ L* → True
By definition L* = {ε} ∪ L⁺, so ε is always included. -
ε ∈ Σ* → True
Σ* contains all strings over Σ including ε. -
ε ∉ Σ⁺ → True
Σ⁺ contains strings of length ≥ 1, so ε is not included.
Final Answer: All statements are true.
5. Grammar in Automata Theory
Grammar in Automata Theory is a formal system that defines rules for generating valid strings of a language. Let understand from very basic
6. Theory of Automata Notations
Notations in Automata Theory are symbols used to represent alphabets, strings, languages, and automata machines.
Common Notations:
-
Σ (Sigma) → Alphabet (finite set of input symbols), e.g., Σ = {a, b}
-
ε (Epsilon) → Empty string (string with length 0)
-
|w| → Length of string w
-
Σ* → Set of all possible strings over alphabet Σ
-
Σ⁺ → Set of all strings over Σ except ε
-
L → A language (set of strings)
-
∅ → Empty language (contains no strings)
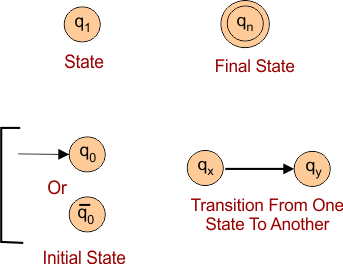
Automata Machine Notations:
-
Q → Finite set of states of the automaton
-
q₀ → Initial (start) state
-
F → Set of final / accepting states
-
δ (delta) → Transition function that shows how the machine moves from one state to another.
Important: Languages are generated according to their grammar and accepted or rejected by automata machines. Automata are abstract machines that accept or reject regular languages.
Note: “It is possible to express all regular languages using Regular Expressions.”
start…
7. Automata Machine and Types
An automaton (like a DFA or NFA) is a state machine that recognizes the language by processing input strings and decides whether they belong to a language.
It consists of:
- States
- Transitions based on input symbols
- A start state
- Accepting (final) state(s)
The automaton takes each input string and processes it through states. If it ends in an accepting state, the string is accepted; otherwise, it’s rejected.
| Note: Some examples of automata machines are Finite Automaton (FA), Pushdown Automaton (PDA), Linear Bounded Automaton (LBA), Turing Machine (TM), Moore machine, Mealy machine etc. |
Validation of an Automata Machine
-
An automaton is designed to recognize a language (a set of valid strings).
-
To validate that the automaton is correct, we test it using strings:
-
It should accept all strings in the language.
-
It should reject all strings not in the language.
-
So, we validate the machine by checking how it behaves on many test strings — both valid and invalid — based on the definition of the target language.
Example:
Let the language L = all binary strings that end in 1.
We can validate the DFA for this language using strings like:
-
“1” → Should be accepted
-
“101” → Accepted
-
“100” → Rejected
-
“” (empty string) → Rejected
If the DFA accepts all strings in L and rejects all others, then it is valid for language L.
Types of Automata Machines
The following table presents information about different types of automata and their respective recognized languages and computational abilities. Each automaton type ranges from regular to ω-regular language classes. The purpose of the table is to demonstrate the varying computational capacities of different automata models.
| Automata Machine | Recognized Languages | Computational Power |
|---|---|---|
| Finite Automaton (FA) | Regular Languages | Limited to Regular Languages |
| Two-Way Finite Automaton | Regular Languages | Same as Finite Automaton |
| Mealy Machine | Output depends on state and input | Limited to Regular Languages |
| Moore Machine | Output depends only on the state | Limited to Regular Languages |
| Pushdown Automaton (PDA) | Context-Free Languages | More powerful than Finite Automaton |
| Linear Bounded Automaton (LBA) | Context-Sensitive Languages | More powerful than PDA |
| Nested Stack Automaton | Certain types of nested structures | More expressive than PDAs |
| Register Machine | Integer functions | Turing-equivalent |
| Turing Machine (TM) | Recursively Enumerable Languages | The most powerful model of computation |
| Multi-Tape Turing Machine | Recursively Enumerable Languages | Same as the Turing Machine |
| Non-deterministic Turing Machine (NDTM) | Recursively Enumerable Languages | Same as the Turing Machine |
| Deterministic Büchi Automaton | ω-limit Languages | Recognizes languages with infinite words satisfying Büchi acceptance condition |
| Nondeterministic Büchi Automaton | ω-Regular Languages | Recognizes languages with infinite words satisfying Büchi acceptance condition |
| Weighted Automaton | Weighted Languages | Assign weights to infinite words |
| Rabin Automaton, Streett Automaton, Parity Automaton, Muller Automaton | ω-Regular Languages | Recognize various classes of ω-regular languages |
8. Chomsky Hierarchy
Proposed by Noam Chomsky.
Types:
-
Type 0 → Recursively Enumerable
-
Type 1 → Context Sensitive
-
Type 2 → Context Free
-
Type 3 → Regular
Circles and arrows form the automata machine, where Circles represent states, and arrows represent transitions. An automaton takes some input strings as input, and this input goes through some states and may be entered in the final state.
Theory of Automata Workflow
Grammar defines production rules, which generate strings (made from input symbols). These strings form a language, which can be accepted or rejected by an automata machine.

The following are some essential elements of the theory of Automata.
1. Grammar
A grammar is a formal set of rules used to generate strings in a language. It includes:
- A start symbol
- Non-Terminals (variables)
- Terminals (alphabet symbols)
- Production rules
Example:
Let the grammar be:
-
Start Symbol: S
-
Terminals: a, b
-
All Production Rules:
-
S → aS
-
S → bS
-
S → a
-
Can represented as S → aS | bS | a
Production rules are the specific rewriting rules in a grammar. They tell how to replace non-terminals with terminals or other non-terminals.
From above grammar, rules are:
-
S → aS
-
S → bS
-
S → a
These allow generating strings like:
-
a
-
aa (S → aS → aa)
-
aba (S → aS → abS → aba)
| Grammar is commonly used to represent a Set of Production Rules with the letter ‘P’.
Note: In all Production rules, P : S → aS | bS | a. Where S → a is one the production rule. |
The followings are the major types of grammar in Automata
-
Type-3: Regular Grammar – Used by Finite Automata to generate Regular Languages.
-
Type-2: Context-Free Grammar (CFG) – Used by Pushdown Automata to generate Context-Free Languages.
-
Type-1: Context-Sensitive Grammar (CSG) – Used by Linear Bounded Automata to generate Context-Sensitive Languages.
-
Type-0: Unrestricted Grammar – Used by Turing Machines to generate Recursively Enumerable Languages.
2. Input Strings
Input strings are sequences of terminal symbols (like a, b) that are derived by applying production rules starting from the start symbol. It is a collection of some symbols from the Sigma (∑). The symbol ‘W’ denotes the string.
String Examples (from the Grammar above):
-
a
-
aa
-
ababa
-
bba
These are input strings we may feed into an automaton for testing.
| Important: Sigma (∑) contains a finite set of symbols known as an alphabet. Symbols involve letters, the alphabet, or any picture. Strings are made from input symbols (∑).
Examples: ∑ = {a, b} , ∑ = {A, B, C, D} , ∑ = {0, 1, ….., 5] |
If ∑ = {x, y}, then various strings that can be generated from ∑ are {x, y, xxx, xyxy, yy, xyy, …..,}.
An empty string, also known as an epsilon string, is a string that contains no symbols or has zero occurrences of symbols. Symbol ‘ε’ denotes the epsilon string. A string’s length refers to the number of characters it contains. Symbol ‘|w|’ denotes the length of that string. If the string is w= 010, its length is 3.
3. Language
A language is the set of all valid strings that can be generated by a grammar. Grammar uses production rules to create the set of strings.
| Note: Languages in automata are classified into four major types: Regular, Context-Free, Context-Sensitive, and Recursively Enumerable, based on the Chomsky Hierarchy. |
Example 01:
The language L = { all strings over a and b that end in a }
So:
-
Valid strings (in the language): a, aa, aba, bba
-
Invalid strings: b, ab, bb
Example: 02
Language (L) = {Set of string of length 2} = {xx, yy, xy, yx} // Finite Language
Example: 03
L2 = {Set of all strings starts with ‘x’} = {x, xx, x, xyy, xyyyy, xyxyxyyyx, ………,} // Infinite Language
4. Automata Machine
An Automaton (plural: Automata) is a mathematical model of a machine that reads input strings from an alphabet and changes states according to rules to decide whether to accept or reject the string.
Formally, an automaton can be represented as a 5-tuple:
M = (Q, Σ, δ, q₀, F)
-
Q → Finite set of states
-
Σ → Input alphabet
-
δ → Transition function (Q × Σ → Q for deterministic machines)
-
q₀ → Start state (q₀ ∈ Q)
-
F → Set of accepting/final states (F ⊆ Q)
Types of Automata
1. Finite Automata (FA)
-
Machines with finite number of states
-
Deterministic FA (DFA) → Each input leads to exactly one next state
-
Non-deterministic FA (NFA) → An input can lead to multiple possible next states
2. Pushdown Automata (PDA)
-
Automata with stack memory
-
Can recognize context-free languages
3. Linear Bounded Automata (LBA)
-
Turing Machine variant with tape length limited by input size
-
Recognizes context-sensitive languages
4. Turing Machine (TM)
-
Most powerful automaton with infinite tape and read/write head
-
Recognizes recursively enumerable languages
Applications Theory of Automata
Following are the applications of thoery of automata
- Compiler Design: Utilizes automata theory for lexical analysis and parsing in compiler construction.
- Parsing and Syntax Analysis: Uses context-free grammars and pushdown automata for analyzing syntax in compilers.
- Lexical Analysis: Applies regular expressions and finite automata to identify tokens in programming language source code.
- Natural Language Processing (NLP): Involves language recognition and syntax analysis for applications like speech recognition.
- Software Engineering: Utilizes automata for specifying and verifying correctness in software systems.
- Model Checking: Verifies system specifications to ensure correctness in hardware and software.
- Network Protocol Design: Uses finite state machines to model and analyze network protocol behavior.
- DNA Computing: Applies automata concepts for solving computational problems using DNA strands.
- Formal Verification: Uses automata for verifying correctness in hardware and software systems.
- Regular Expressions in Text Processing: Widely used for searching and data extraction tasks.
- Databases: Applies finite automata and regular expressions for query processing and pattern matching.
- VLSI Design: Utilizes automata theory in modeling and optimizing sequential circuits in VLSI.
- Robotics: Implements finite state machines to model and control robot behavior based on sensory input.