










Lock Based Protocol in DBMS
A Lock-Based Protocol in DBMS is a mechanism used to control access to a database’s resources during concurrent transaction execution. When multiple users or processes access the same data simultaneously, it can lead to conflicts, such as lost updates, temporary inconsistency, or uncommitted data visibility. Lock-based protocols prevent these issues by “locking” data that a transaction is using, preventing other transactions from accessing it simultaneously.
These locks help maintain data integrity, prevent conflicts, and ensure serializability—that is, the system guarantees that transactions produce results equivalent to some serial execution of those transactions.
Types of Locks in Lock-Based Protocols
There are two primary types of locks in DBMS: Shared Locks (S-locks) and Exclusive Locks (X-locks). Each type serves a specific purpose in transaction control:
1. Shared Lock
A Shared Lock (S-lock), also known as a Read-Only Lock, is a fundamental concept in database management systems (DBMS) used to control access to data during concurrent transactions. It allows transactions to perform read operations without causing conflicts but prevents any modifications to the locked data. Let’s break down the concept in more detail.
What is a Shared Lock (S-lock)?
In a Shared Lock, a transaction can read a data item, but it cannot modify the locked data. The key feature of shared locks is that multiple transactions can hold a shared lock on the same data simultaneously, allowing them to read the data concurrently. However, while the lock is held, no other transaction is permitted to modify the data.
How Does a Shared Lock Work?
When a transaction (say T1) holds a shared lock on a data item (say A), it can perform read operations on A. If another transaction (say T2) wants to read the same data (A), it can also acquire a shared lock on A without having to wait for T1 to release its lock. This is because reading data (Read-Read operation) does not cause any conflict.
However, if a transaction (say T3) wants to modify the data (A) while T1 and T2 are holding shared locks, it will not be allowed. Modifying data (Write operation) is not compatible with the shared lock, as it could lead to data inconsistency.
Key Characteristics of Shared Locks
- Read-Only Access: Shared locks are used when a transaction needs to read data without making any changes. They are designed to prevent conflicting write operations while allowing multiple transactions to perform read operations concurrently.
- Concurrency: Since multiple transactions can acquire shared locks on the same data at the same time, shared locks enable high concurrency in DBMS. This is particularly beneficial when users need to access the same data simultaneously without making modifications.
- Conflict-Free: Shared locks do not conflict with other shared locks, meaning that multiple transactions can hold shared locks on the same data at the same time. However, they conflict with exclusive locks (X-locks) because an exclusive lock would require exclusive access to the data, preventing other transactions from reading or writing to it.
Example of Shared Lock in Action
Imagine an online e-commerce website where multiple users are browsing a product catalog. Each user is performing a read operation, viewing the product details. In this case, each user can acquire a shared lock on the product catalog data, allowing them to view the data without waiting for other users to finish. Since all transactions are read-only, there is no conflict.
However, if one of the users wants to update the product catalog (for example, adding a new product or changing a price), an exclusive lock would be required. This would prevent other users from reading or writing to the product catalog until the update operation is complete.
Advantages of Shared Locks
-
Concurrency: Shared locks allow multiple transactions to access the same data for reading purposes, increasing the overall throughput and performance of the database.
-
Non-Blocking for Reads: Since read operations are allowed concurrently, shared locks do not block other transactions from reading the same data, reducing wait times.
-
Simple to Implement: The shared lock mechanism is relatively straightforward, providing a basic but effective way of ensuring data consistency while enabling concurrent read access.
Limitations of Shared Locks
-
No Write Operations: Shared locks only allow read operations. If a transaction needs to modify data, it cannot do so while a shared lock is held.
2. Exclusive Lock
An Exclusive Lock (X-lock) ensures that only one transaction can perform both read and write operations on a data item at a time. If a transaction needs to update data (whether it involves reading or modifying the data), it must first acquire an exclusive lock on that data. This means that once an exclusive lock is applied, no other transaction can either read or write the locked data until the lock is released.
In other words, exclusive locks provide the highest level of control over data by preventing all other transactions from interacting with the locked data, ensuring data integrity and conflict-free operations.
How Does an Exclusive Lock Work?
When a transaction (say T1) acquires an exclusive lock on a data item (say A), T1 can read and modify the data without any interference from other transactions. However, if another transaction (say T2) wants to access the same data (A), it must wait until T1 releases the exclusive lock.

This ensures that T2 cannot modify or even read the locked data, which prevents potential issues like dirty writes, lost updates, or data anomalies.
Key Characteristics of Exclusive Locks
-
Read and Write Operations: Unlike shared locks that only allow read access, exclusive locks enable a transaction to both read and write data. This makes them ideal for operations where data needs to be modified or updated.
-
Conflict Prevention: Exclusive locks prevent conflicts by ensuring that only one transaction can access the data at any given time, thereby preventing other transactions from reading or modifying the same data simultaneously.
-
Single Transaction Control: Only one transaction can hold an exclusive lock on a particular data item, ensuring exclusive control over that piece of data. This feature is essential for tasks like updating records, deleting data, or inserting new records.
Example of Exclusive Lock in Action
Imagine a scenario where a user is updating their profile information on an e-commerce website. To modify the profile data (e.g., change the email address or shipping address), the system will apply an exclusive lock on that user’s profile data.
While T1 holds the exclusive lock, T2 (another user or transaction) cannot perform any action on the same profile data, not even reading the information, until T1 finishes updating the profile and releases the lock. This prevents potential conflicts like reading stale data or overwriting the profile while it is being updated.
Advantages of Exclusive Locks
-
Ensures Data Integrity: By preventing any concurrent read or write operations on the same data item, exclusive locks ensure that the data remains consistent and free from conflicts during update operations.
-
Ideal for Write Operations: Exclusive locks are necessary for transactions that need to modify data. They guarantee that no other transaction can interfere with the ongoing operation.
-
Prevents Dirty Writes: Since no other transaction can access the locked data, exclusive locks prevent dirty writes (where one transaction overwrites the uncommitted changes of another).
Limitations of Exclusive Locks
-
Blocking Other Transactions: The main disadvantage of exclusive locks is that they can cause blocking. If T1 holds an exclusive lock, other transactions (T2, T3, etc.) must wait until T1 releases the lock. This can lead to delays and lower concurrency in high-transaction environments.
-
Reduced System Throughput: Since exclusive locks prevent other transactions from accessing the locked data, they can reduce the system throughput by limiting the number of concurrent transactions.
-
Risk of Deadlock: Exclusive locks, like any locking mechanism, can lead to deadlocks. If T1 holds an exclusive lock on Data A and is waiting for a lock on Data B, and at the same time, T2 holds an exclusive lock on Data B and is waiting for Data A, both transactions will be blocked indefinitely, causing a deadlock.
Shared and Exclusive Locks on Same Data Items
In Database Management Systems (DBMS), the Compatibility Lock Table is essential for ensuring proper transaction management when multiple transactions want to read or write the same data item. Shared and Exclusive locks help prevent conflicts, such as lost updates or dirty reads, by ensuring that only one transaction can modify data at a time, while multiple transactions can read the same data concurrently under certain conditions.
Suppose T1 and T2 are parallel transactions, and both want to perform read and write operations on the same data, say “A”. A shared lock is denoted by “S,” and an Exclusive lock is denoted by “X”.
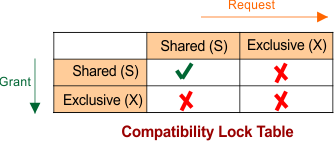
Case Breakdown
Case 1: Shared Lock to Shared Lock (S to S)
-
Scenario: T1 has a shared lock on Data A, and T2 wants to acquire a shared lock on Data A as well.
-
Explanation: This is allowed because Read-Read is not a conflict. Both transactions are only reading the data, so there’s no need to block T2 from acquiring the shared lock.
-
Conclusion: Multiple transactions can hold shared locks on the same data without causing issues.
Case 2: Shared Lock to Exclusive Lock (S to X)
-
Scenario: T1 has a shared lock on Data A, and T2 wants to acquire an exclusive lock on Data A.
-
Explanation: This is not allowed because Read-Write is a conflict. T2 wants to write to the data, which could result in overwriting the changes T1 is reading.
-
Conclusion: A shared lock cannot be upgraded to an exclusive lock while other transactions still have shared locks on the same data.
Case 3: Exclusive Lock to Shared Lock (X to S)
-
Scenario: T1 has an exclusive lock on Data A, and T2 wants a shared lock on Data A.
-
Explanation: This is not allowed because Write-Read is a conflict. T1 is modifying the data, and T2 is trying to read it. If T2 reads the data while T1 is writing, it may get stale or inconsistent data.
-
Conclusion: If a transaction has an exclusive lock, no other transaction can hold any kind of lock (shared or exclusive) on the same data until the exclusive lock is released.
Case 4: Exclusive Lock to Exclusive Lock (X to X)
-
Scenario: T1 has an exclusive lock on Data A, and T2 wants to acquire an exclusive lock on Data A.
-
Explanation: This is not allowed because Write-Write is a conflict. Both transactions want to modify the data, which could result in conflicts and lost updates.
-
Conclusion: If a transaction holds an exclusive lock, no other transaction can acquire an exclusive lock on the same data until the original transaction releases its lock.
Shared and Exclusive Locks on Different Data Items
No Issue at all. The parallel usage of shared and exclusive locks on different data items allows for efficient, concurrent operations in the database. This increases the overall performance by enabling multiple transactions to run at the same time without interfering with each other, as long as they are working with different data items. However, conflicts occur when both types of locks are applied to the same data item, leading to delays and blocking.
Here’s how it works:
-
Transaction T1 might hold a shared lock on Data A, allowing other transactions to read Data A.
-
Transaction T2 might hold an exclusive lock on Data B, allowing it to modify Data B without interference from other transactions.
In this case, T1 and T2 are working on different pieces of data simultaneously, so they can proceed without blocking each other.
Problems in Lock-Based Protocol in DBMS
When the Shared or Exclusive locking is given properly, then there may still exist the following problem
Problem 1: The produced schedule through shared-exclusive locking is not always a serial.
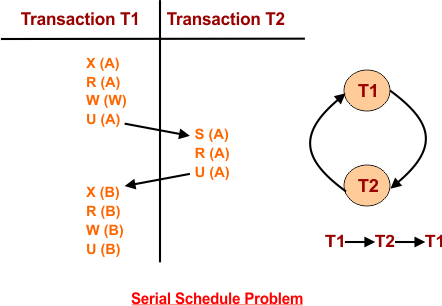
Explanation: See the above example where read/write locking is given properly, but still, a loop is present in the schedule of T1 and T2. We know if a loop is there, then it may or may not be a serial
Problem-2: Produced schedule through Shared-Exclusive locking may be irrecoverable
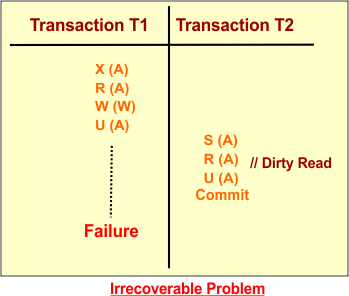
Problem 3: The produced schedule through Shared-Exclusive locking may contain a deadlock problem
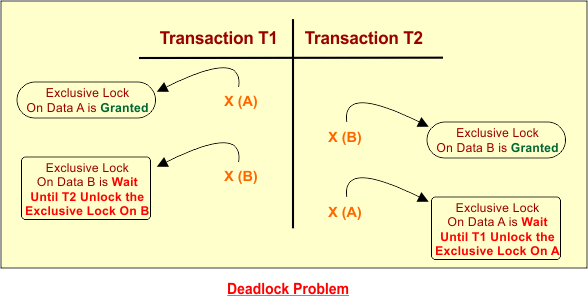
Problem-4: Produced schedule through Shared-Exclusive locking may still contain starvation

Explanation
- T2 requests for a shared lock on data “A,” which is granted directly. Now, let’s suppose T1 requests an exclusive lock on data “A,” which will not be granted until T2 unlocks data A.
- Suppose T2 was unlocking data A, and T3 also acquired Shared-lock on the same data A. It is possible to share lock and shared lock at a time on the same data. So, T1 has to wait until T3 unlocks the A.
- Suppose T3 was unlocking data A, and T4 also gets the Shared-lock on the same data A. Now, T1 has to wait until T4 unlocks the A.
- So, Transaction T1 waits from time 2 to time 8 to get an exclusive lock on data “A”. Therefore, It is a starvation case.
Problem-5: Produced schedule through Shared-Exclusive locking may cause a cascading Rollback problem
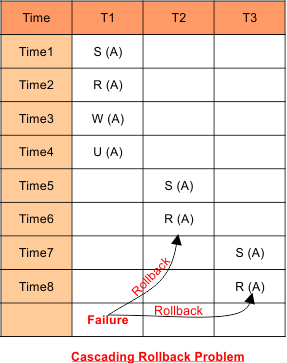
Explanation: If the rollback of one transaction causes the rollback of other dependent transactions, it is called cascading rollback.
How Lock-Based Protocols Work
Lock-based protocols work by enforcing locking rules to maintain a transaction’s isolation and ensure that no two transactions violate the serializability principle. These protocols are generally two-phase locking protocols, which can be broken down into two phases:
i. Growing Phase:
-
A transaction can acquire locks but cannot release any locks.
-
During this phase, the transaction gains exclusive or shared locks on the data items it intends to read or modify.
ii. Shrinking Phase:
-
After acquiring the necessary locks, the transaction releases its locks and cannot acquire any new locks.
-
This phase ensures that the transaction does not enter a state where it might conflict with others.
This two-phase locking protocol ensures that transactions are serializable and avoids common issues like deadlocks and conflicts during transaction execution.
Types of Lock-Based Protocols
There are several types of lock-based protocols used in DBMS to manage locks effectively:
i. Basic Locking Protocol:
-
A transaction locks all the data it needs to access before performing any operations, and it releases the locks once the transaction is complete.
ii. Two-Phase Locking (2PL):
-
As mentioned, this protocol ensures that a transaction acquires all the necessary locks before releasing any. It guarantees serializability and is widely used in modern DBMS.
iii. Strict Two-Phase Locking (S2PL):
-
In this variant, the transaction holds all its locks until it commits or aborts. This strict version eliminates cascading rollbacks.
iv. Rigorous Two-Phase Locking (R2PL):
-
Here, a transaction cannot release any locks until it commits. This approach is even more stringent, ensuring serializability and recoverability.
Advantages of Lock-Based Protocols
- Data Consistency: Lock-based protocols prevent conflicting transactions from accessing the same data simultaneously, ensuring consistent data and preventing data anomalies.
- Transaction Isolation: By enforcing locks, these protocols provide transaction isolation, which guarantees that operations of one transaction do not affect others.
- Avoidance of Inconsistent States: With proper locking, DBMS ensures that transactions only access data in a stable state, preventing issues like dirty reads and phantom reads.
- Deadlock Detection: Some advanced lock-based protocols include mechanisms to detect deadlocks—situations where two or more transactions wait on each other to release locks. These protocols resolve deadlocks by aborting one of the transactions.
Challenges and Limitations
While lock-based protocols are essential for transaction management in DBMS, they also come with challenges:
- Deadlock: If two or more transactions hold locks and wait for each other’s resources, they can enter a deadlock state. Deadlock prevention, detection, and resolution strategies are critical for maintaining system performance.
- Lock Contention: When many transactions request the same lock on data, it can cause lock contention, leading to delays and performance issues.
- Overhead: Managing locks and enforcing the protocol introduces some performance overhead, especially in systems with many concurrent transactions.
- Starvation: In certain situations, transactions may be blocked from acquiring the necessary locks for a long time, leading to starvation.
Conclusion
Lock-based protocols are fundamental to ensuring the integrity, isolation, and serializability of transactions in a DBMS. By using locks effectively, these protocols prevent issues like dirty reads, lost updates, and data anomalies. However, understanding the trade-offs, such as deadlocks and lock contention, is crucial to optimizing DBMS performance. In real-world applications, these protocols are essential for maintaining smooth, efficient, and reliable database systems.