










Candidate Key in DBMS
In Database Management Systems (DBMS), a candidate key is a set of one or more attributes (columns) that can uniquely identify a record (row) in a table. A table can have multiple candidate keys, but only one of them is chosen as the primary key.
Key Points about Candidate Key:
-
Uniqueness: Every candidate key must be able to uniquely identify each row in the table.
-
No Redundancy: A candidate key is a minimal superkey with only essential attributes for uniqueness.
-
Multiple Candidate Keys: A table can have more than one candidate key. The user chooses one of them to be the primary key. The others are called alternate keys.
| How to Find the Candidate Key in DBMS?
Answer: We can find all possible candidate keys by using the closure method, which is applied on the given Relational table and functional dependencies. |
Example of Candidate Keys in DBMS
Consider a Student table with the following columns:
| Student_ID | Phone | Name | |
|---|---|---|---|
| 1 | john@email.com | 1234567890 | John |
| 2 | jane@email.com | 9876543210 | Jane |
-
Student_ID: Can uniquely identify each student.
-
Email: Can also uniquely identify each student.
-
Phone: Similarly, it can uniquely identify each student.
In this case, Student_ID, Email, and Phone are all candidate keys because each of them can uniquely identify a student. However, one of them would be chosen as the primary key. Name cannot use as candidate key
Key Properties of Candidate key in DBMS
Here are key properties of candidate key in DBMS
- Unique: A candidate key uniquely identifies each row in a table.
- Minimal: Every attribute in the key is necessary. Removing any attribute will make it unable to uniquely identify rows.
- No NULL Values: A candidate key cannot contain NULL values because every record must be identifiable.
- Primary and Alternate Keys: One candidate key is chosen as the Primary Key, while the remaining candidate keys are called Alternate Keys.
An Algorithm to find Candidate Keys in DBMS
Here is an algorithm that will calculate all possible candidate keys when the following data is given
- Relation (R) with some attributes
- Functional dependencies (FD’s) over R
Step 01: Find the Initial Minimal Super Key
Take all attributes of relation (R) that become the initial minimal super key (Initially Minimal Super Key) because they can determine themselves through the reflexive property.
Example:
- For relation R(A, B, C, D, E)
- Initial Minimal Super Key = {A, B, C, D, E}
Since this set contains all attributes of the relation, it can uniquely identify every tuple and is therefore a super key.
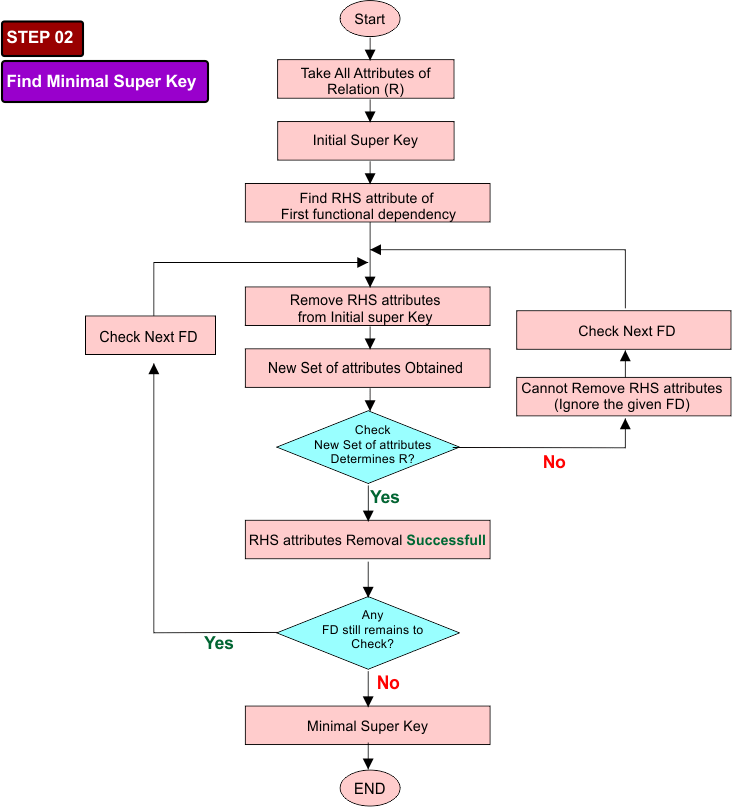
Step 02: Find the minimal super key from the Initial Minimal Super Key
Examine each functional dependency (FD) one by one. Consider the attribute(s) appearing on the right-hand side (RHS) of each FD and try removing them from the initial minimal super key.
- After removing the RHS attribute(s), compute the closure of the remaining attributes. If the closure still determines the entire relation R, the removal is valid; otherwise, restore the removed attribute(s) and proceed to the next FD.
Continue this process for all FDs until no further attributes can be removed. The resulting set of attributes is the minimal super key.
Flowchart of Step 02:
Example of Step 02:
Relation R(A, B, C, D, E, F) with following Functional Dependencies is given
- A → B
- A → C
- C → D
- D → E
Let’s compute the minimal super key, which will update the intial minimal super key
- Initial minimal Super Key = {A, B, C, D, E, F}
- Check first FD, Remove B because A → B, since the closure of the remaining minimal super key still determines all relation R. New set of attributes = {A, B, C, D, E, F} – {B} = {A, C, D, E, F}
- Check Second FD, Remove C because A → C, since the closure of the remaining minimal super key still determines all relation R. New set of attributes = {A, C, D, E, F} – {C} = {A, D, E, F}
- Check third FD, Remove D because A → C → D, since the closure of the remaining minimal super key still determines all relation R. New set of attributes = {A, D, E, F} – {D} = {A, E, F}
- Check Last FD, Remove E because A → C → D → E, since the closure of the remaining minimal super key still determines all relation R. New set of attributes = {A, E, F}-{E} = {A, F}
Since (A,F)⁺ = {A, B, C, D, E, F}, the it is the minimal super key = {A, F}. Minimal super is further used in the next step to decide whether it is a candidate key or not.
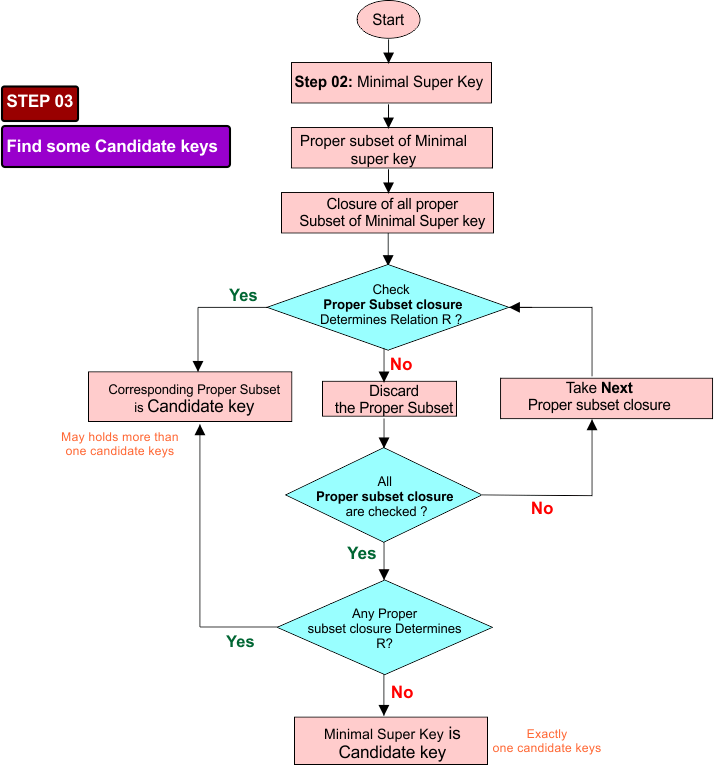
Step 03: Verification of SK₂ for Candidate Key
Take all proper subsets of minimal super key and compute the closure of each subset.
- If none of the proper subsets can determine all attributes of relation R, then minimal super key itself is a candidate key.
- If a proper subset determines all attributes of R, then minimal super key is not minimal, and that subset becomes the candidate key.
Flowchart of Step 03
Example of Step 03
From Step 02, we obtained: minimal super key = {A, F}
Step 1: Find all proper subsets of minimal super key
Proper subsets of {A, F} are:
- {A}
- {F}
Step 2: Compute the closure of each subset
For {A}⁺:
- {A}⁺ = {A, B, C, D, E}
- Since F is missing, {A}⁺ ≠ R
Therefore, {A} is not a candidate key.
For {F}⁺:
- {F}⁺ = {F}
- Since it does not determine any other attributes, {F}⁺ ≠ R
Therefore, {F} is not a candidate key.
Step 3: Conclusion
No proper subset of minimal super key = {A, F} determines all attributes of relation R. Therefore, the minimal super key is minimal and becomes the first candidate key.
Candidate Key = minimal super key = {A, F}.
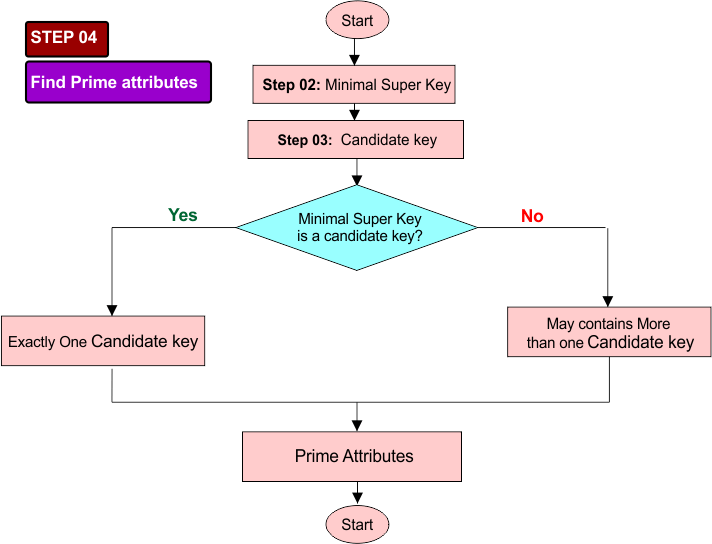
Step 04: Check Prime attributes From candidate keys
Note down all the attributes of candidate keys, which will be the prime attributes because they are participating in a candidate key.
Flowchart of step 04
Example of step 04
As Step 03 produced the following candidate keys: {A, F}. Since the attributes A and F participate in the candidate key, they are prime attributes.
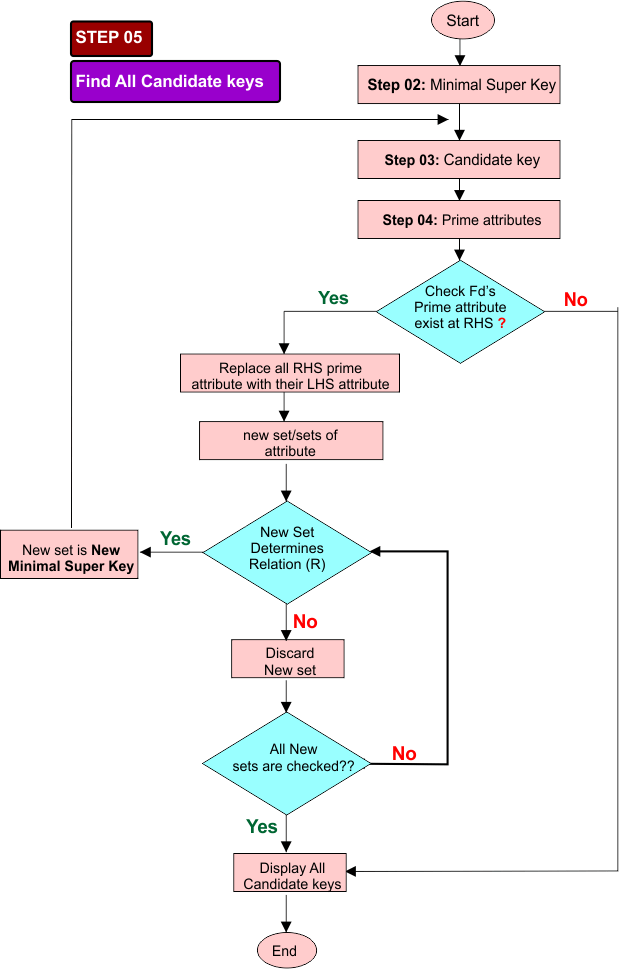
Step 05: Check for More Candidate Keys Possibilities
Check all functional dependencies (FD’s) again.
If a prime attribute appears on the RHS of an FD, replace that prime attribute in the candidate key with the attributes on the LHS of that FD. In this way, a new set of attribute/attributes is generated.
- If the closure of this new set determines the relation (R), then it will be a new minimal super key; otherwise, discard it
- Now apply step 3,4 and 5 to the new minimal super key to generate more candidate keys, repeat this process untill no new set for the super key remains.
Otherwise, Step 05 cannot generate a new minimal super key, only we get candidate keys earlier from step 03
Flowchart of STEP 05
Example of step 05
Candidate Key = {A, F}, getting already from step 03
STEP 6: Last Step to find some more Candidate Keys
Check the LHS of every FD. If the LHS of any FD contains a candidate key, then its RHS may also be a candidate key.
Example of step 06
None of the FD contains a candidate key at LHS, so no more candidate keys can be derived.
Step 07 Result:
List of candidate keys is given below
- {A,F}
Find Candidate Keys in DBMS – Example – 1
When the relation R (A, B, C, D, E) has the following functional dependencies, then find all possible candidate keys
- A → BC
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains five attributes {A, B, C, D, E}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D, E}
STEP 02: Updated Minimal Super Key
There is only a single functional dependency (FD): A → BC.
Take the RHS of given First FD which is {B, C}, discard it from the initial minimal super key {A,B,C,D,E}
- {A,B,C,D,E} – {B,C} = {A,D,E}
Now find the closure of {A, D, E}.
- {A,D,E}+ = {A,B,C,D,E}
It determines the entire relation (R) {A, B, C, D, E}. So, the discard is successful. No other functional dependencies exist, so no further attributes can be discarded. So, Updated minimal super key = {A,D,E}
The following diagram explains all the procedure

STEP 03: Verification of Minimal Super Key for Candidate key
Take Proper Subset of updated minimal super key which is {A,D,E} = {A}, {D}, {E}, {A,D}, {A,E}, {D,E}
{A}+ = {A,B,C}
{D}+ = {D}
{E}+ = {E}
{A,D}+ = {A,D,B,C}
{A,E}+ = {A,E,B,C}
{D,E}+ = {D,E}
None of the proper subsets can determine all attributes of relation R, So the minimal super key itself is a candidate key, which is {A, D, E}. The following diagram shows this process

STEP 04: Check Prime attributes from candidate keys
{A}, {D}, and {E} are prime attributes because they part of candidate key. The following diagram shows it

STEP 05: Check for More Candidate Keys Possibilities
As none of the prime attributes appear on the RHS of any FD, So step 05 cannot generate any new candidate key
Final Candidate Key = {A,D,E}

STEP 6: Last Step to find some more Candidate Keys
None of the FDs contain the candidate key {A,D,E} on the LHS, so no additional candidate keys can be derived.
Step 07 Result:
List of candidate keys is given below
- {A,D,E}
Find Candidate Keys in DBMS – Example – 2
When the relation R (A, B, C, D) has the following functional dependencies, then find all possible candidate keys
- ABC → D
- AB → CD
- A → BCD
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D}. So the initial minimal superkey contains all these attributes.
- Initial minimal super key = {A, B, C, D}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: ABC → D
Take the RHS of First FD, which is {D}, discard it from the initial minimal super key {A, B, C, D}
- {A,B,C,D} – {D} = {A,B,C}
Now find the closure of {A, B, C}.
- {A,B,C}+ = {A,B,C,D}
{A,B,C}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,B,C}
Second FD: AB → CD
Take the RHS of Second FD, which is {CD}, discard it from the Updated minimal super key {A, B, C}
- {A,B,C} – {C,D} = {A,B}
Now find the closure of {A, B}.
- {A,B}+ = {A,B,C,D}
{A,B}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,B}
Third FD: A → BCD
Take the RHS of Third FD, which is {BCD}, discard it from the updated minimal super key {A, B}
- {A,B} – {B,C,D} = {A}
Now find the closure of {A}.
- {A}+ = {A,B,C,D}
{A}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A}
No other functional dependencies exist, so that no further attributes can be discarded. So,Final updated minimal super key = {A}. The following diagram explains all the procedures

STEP 03: Verification of Minimal Super Key for Candidate key
Take a proper subset of the updated minimal super key, which is {A} = { }. None of the proper subsets exists for {A}, so the minimal super key itself is a candidate key {A}. The following diagram explains all the procedures

STEP 04: Check Prime attributes from candidate keys
{A} is a prime attribute because it is part of the candidate key. The following diagram shows it

STEP 05: Check for More Candidate Keys Possibilities
As none of the prime attributes appear on the RHS of any FD, So step 05 cannot generate any new candidate key
Final Candidate Key = {A}

STEP 6: Last Step to find some more Candidate Keys
FD (A → BCD) contains a candidate key {A} at LHS, but the closure of the RHS of this FD does not derive all attributes of the relation. So {BCD} is not valid for the candidate key
Step 07 Result:
List of candidate keys is given below
- {A}
Find Candidate Keys in DBMS – Example – 3
When the relation R (A, B, C, D) has the following functional dependencies, then find all possible candidate keys
- B → ACD
- ACD → B
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D}
STEP 02: Updated Minimal Super Key
There are two functional dependencies (FD)
First FD: B→ ACD
Take the RHS of First FD, which is {ACD}, discard it from the initial minimal super key {A, B, C, D}
- {A,B,C,D} – {A,C,D} = {B}
Now find the closure of {B}.
- {B}+ = {A,B,C,D}
{B}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {B}
Second FD: ACD → B
Take the RHS of Second FD, which is {B}, discard it from the Updated minimal super key {B}
- {B} – {B} = { }
Now find the closure of { }.
- { }+ = { }
{ }+ determines nothing. So, the discard is not successful. Now Updated minimal super key remains unchanged = {B}
No other functional dependencies exist, so that no further attributes can be discarded. So,Final updated minimal super key = {B}. The following diagram explains all the procedures
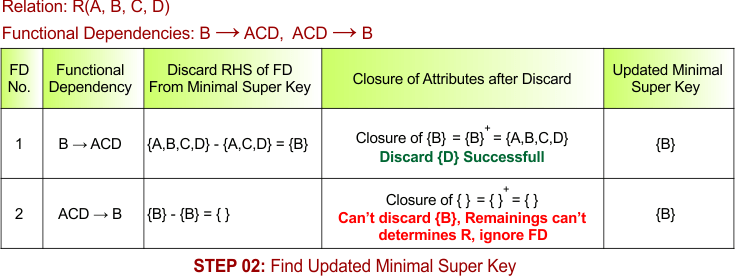
STEP 03: Verification of Minimal Super Key for Candidate key
Take a proper subset of the updated minimal super key, which is {B} = { }. None of the proper subsets exists for {B}, so the minimal super key itself is a candidate key {B}. The following diagram explains all the procedures

STEP 04: Check Prime attributes from candidate keys
{B} is a prime attribute because it is part of the candidate key. The following diagram shows it

STEP 05: Check for More Candidate Keys Possibilities
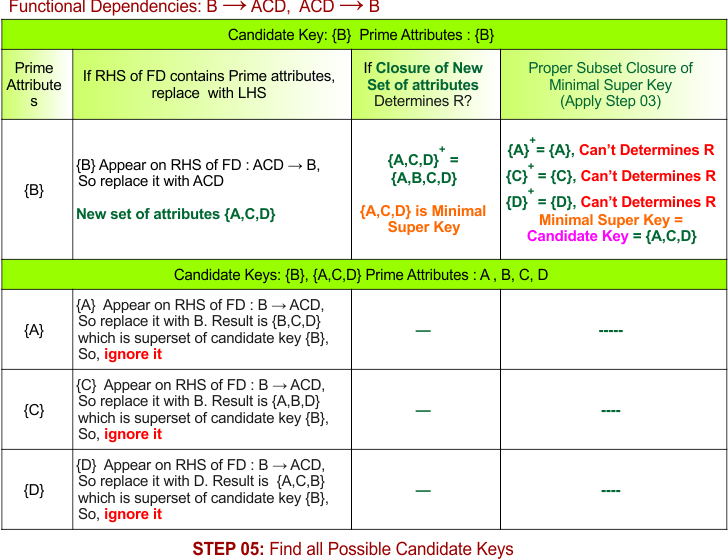
As the prime attribute {B} appears on the RHS of any FD, step 05 can generate any new candidate key, replace {B} with {A, C, D} in the candidate key. So, {A, C, D} is a new minimal super key. Apply steps 3, 4, and 5, and we get {A, C, D} is also a candidate key
- Final Candidate Keys = {B}, {A,C,D}
The following diagram shows the process
STEP 6: Last Step to find some more Candidate Keys
- FD (B → ACD) contains a candidate key {B} at LHS, and it’s RHS is already a candidate key which derived in step 05
- FD (ACD → B) contains a candidate key {ACD} at LHS, and it’s RHS is already a candidate key which derived in step 03
No further candidate key is derived.
Step 07 Result:
List of candidate keys is given below
- {B}
- {A,C,D}
Find Candidate Keys in DBMS – Example – 4
When the relation R (A, B, C, D) has the following functional dependencies, then find all possible candidate keys
- A → B
- B → C
- C → A
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: A → B
Take the RHS of First FD, which is {B}, discard it from the initial minimal super key {A, B, C, D}
- {A,B,C,D} – {D} = {A,C,D}
Now find the closure of {A, C, D}.
- {A,B,C}+ = {A,B,C,D}
{A,C,D}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,C,D}
Second FD: B → C
Take the RHS of Second FD, which is {C}, discard it from the Updated minimal super key {A, C, D}
- {A,C,D} – {C} = {A,D}
Now find the closure of {A, D}
- {A,D}+ = {A,B,C,D}
{A,D}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,D}
Third FD: C → A
Take the RHS of Third FD, which is {A}, and discard it from the updated minimal super key {A}
- {A,D} – {A} = {D}
Now find the closure of {D}.
- {D}+ = {D}
{D }+ cannot determine the relation. So, the discard is not successful. Now Updated minimal super key remains unchanged = {A,D}
No other functional dependencies exist, so that no further attributes can be discarded. So, the final updated minimal super key = {A, D}. The following diagram explains all the procedures

STEP 03: Verification of Minimal Super Key for Candidate key
Take Proper Subset of updated minimal super key which is {A,D} = {A}, {D}
- {A}+ = {A,B,C}
- {D}+ = {D}
None of the proper subsets can determine all attributes of relation R, So the minimal super key itself is a candidate key, which is {A, D}. The following diagram shows this process

STEP 04: Check Prime attributes from candidate keys
{A} and {D} are prime attributes because they are part of the candidate key. The following diagram shows it

STEP 05: Check for More Candidate Keys Possibilities
As the prime attribute {A} appears on the RHS of the third FD, So step 05 can generate any new candidate key, simply replace {A} with {C} in the candidate key. So, {C, D} is a new minimal super key, Apply step 3,4 and 5, and we get {C, D} is also a candidate key
As the prime attribute {C} appears on the RHS of the second FD, So step 05 can generate any new candidate key, simply replace {C} with {B} in the candidate key. . So, {B,D} is new minimal super key, Apply step 3,4 and 5, and we get {B, D} is also a candidate key
Final Candidate Keys = {A,D}, {C,D}, {B,D}

STEP 6: Last Step to find some more Candidate Keys
None of the FD contains a candidate key at LHS, so no more candidate keys can be derived. SO, no further candidate key is derived.
Step 07 Result:
List of candidate keys is given below
- {A,D}
- {C,D}
- {B,D}
Find Candidate Keys in DBMS: Example – 5
When the relation R (A, B, C, D) has the following functional dependencies, then find all possible candidate keys
- AB → CD
- D→ A
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: AB → CD
Take the RHS of First FD, which is {CD}, discard it from the initial minimal super key {A, B, C, D}
- {A,B,C,D} – {C,D} = {A,B}
Now find the closure of {A, B}.
- {A,B}+ = {A,B,C,D}
{A,B}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,B}
Second FD: D → A
Take the RHS of second FD, which is {A}, and discard it from the updated minimal super key {A,B}
- {A,B} – {A} = {B}
Now find the closure of {B}.
- {B}+ = {B}
{B}+ cannot determine the relation. So, the discard is not successful. Now Updated minimal super key remains unchanged = {A,B}
No other functional dependencies exist, so that no further attributes can be discarded. So, the final updated minimal super key = {A, B}. The following diagram explains all the procedures
STEP 03: Find Candidate key from Minimal Super Key
Take Proper Subset of updated minimal super key which is {A,B} = {A}, {B}
- {A}+ = {A}
- {B}+ = {B}
None of the proper subsets can determine all attributes of relation R, So the minimal super key itself is a candidate key, which is {A, B}. The following diagram shows this process

STEP 04: Find Prime Attributes
{A} and {B} are prime attributes because they are part of the candidate key. The following diagram shows it

STEP 05: Find all possible Candidate Keys
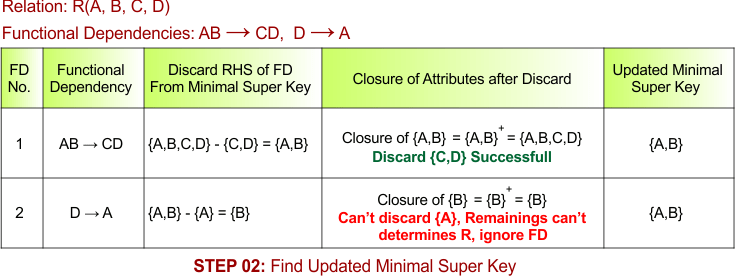
As the prime attribute {A} appears on the RHS of the second FD, So step 05 can generate any new candidate key, simply replace {A} with {D} in the candidate key. So, {D,B} is a new minimal super key. Apply steps 3, 4, and 5, and we get {D, B} is also a candidate key
Prime attributes “B” and “D” do not appear on the RHS of any FD. So, no new minimal super key is derived for further candidate keys
Final Candidate Keys = {A,B}, {D,B}

Find Candidate Keys in DBMS: Example – 6
When the relation R (A, B, C, D, E, F) has the following functional dependencies, then find all possible candidate keys
- AB → C
- C→ D
- B → AE
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains six attributes {A, B, C, D, E, F}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D, E, F}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: AB → C
Take the RHS of First FD, which is {C}, discard it from the initial minimal super key {A, B, C, D, E, F}
- {A,B,C,D, E, F} – {C} = {A,B,D, E, F}
Now find the closure of {A, B, D, E, F}.
- {A, B, D, E, F}+ = {A, B, C, D, E, F}
{A,B,D, E, F}+ determines the entire relation {A, B, C, D, E, F}. So, the discard is successful. Now Updated minimal super key = {A, B, D, E, F}
Second FD: C → D
Take the RHS of Second FD, which is {D}, discard it from the Updated minimal super key {A, B,E,F}
- {A,B,D,E,F} – {D} = {A,B, E, F}
Now find the closure of {A, B, E, F}.
- {A,B, E, F}+ = {A,B,C,D, E,F }
{A,B, E, F}+ determines the entire relation {A, B, C, D, E, F}. So, the discard is successful. Now Updated minimal super key = {A,B, E, F}
Third FD: B → AE
Take the RHS of Third FD, which is {AE}, discard it from the updated minimal super key {A, B, E, F}
- {A,B, E, F} – {A,E} = {B,F}
Now find the closure of {B, F}.
- {B,F}+ = {A,B,C,D, E,F }
{B,F}+ determines the entire relation {A, B, C, D, E,F}. So, the discard is successful. Now Updated minimal super key = {B,F}
No other functional dependencies exist, so that no further attributes can be discarded. So,Final updated minimal super key = {B,F}. The following diagram explains all the

STEP 03: Find Candidate key from Minimal Super Key
Take Proper Subset of updated minimal super key which is {A,D} = {A}, {D}
- {B}+ = {A,B,C,D,E}
- {F}+ = {F}
None of the proper subsets can determine all attributes of relation R, so the minimal super key itself is a candidate key, which is {B, F}. The following diagram shows this process
 error
error
STEP 04: Find Prime Attributes
{B} and {F} are prime attributes because they are part of the candidate key. The following diagram shows it

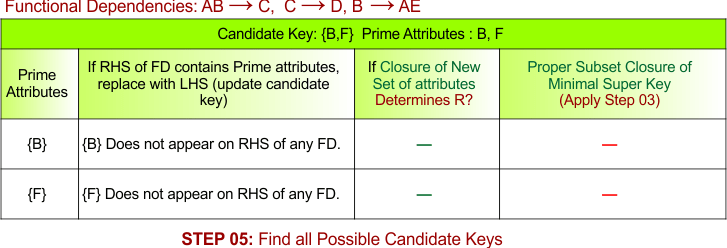
STEP 05: Find all possible Candidate Keys
Prime attributes “B” and “F” do not appear on the RHS of any FD. So, no new minimal super key is derived for further candidate keys
Final Candidate Keys = {B,F}
STEP 6: Last Step to find some more Candidate Keys
None of the FD contains a candidate key at LHS, so no more candidate keys can be derived. SO, no further candidate key is derived.
Step 07 Result:
The list of candidate keys is given below
- {B, F}
Find Candidate Keys in DBMS: Example – 7
When the relation R (A, B, C, D) has the following functional dependencies, then find all possible candidate keys
- AB→ CD
- C→ A
- D→ B
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: AB → CD
Take the RHS of First FD, which is {B}, discard it from the initial minimal super key {A, B, C, D}
- {A,B,C,D} – {C,D} = {A,B}
Now find the closure of {A, B}
- {A,B}+ = {A,B,C,D}
{A,B}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,B}
Second FD: C → A
Take the RHS of Second FD, which is {A}, and discard it from the updated minimal super key {A, B}
- {A,B} – {A} = {B}
Now find the closure of {B}
- {B}+ = {B}
{B}+ does not determines the entire relation {A, B, C, D}. So, the discard cannot be successful. Now Updated minimal super key = {A,B}
Third FD: D → B
Take the RHS of Third FD, which is {B}, and discard it from the updated minimal super key {A,B}
- {A,B} – {B} = {A}
Now find the closure of {A}.
- {A}+ = {A}
{B}+ does not determines the entire relation {A, B, C, D}. So, the discard cannot be successful. Now Updated minimal super key = {A,B}
No other functional dependencies exist, so that no further attributes can be discarded. So, the final updated minimal super key = {A, B}. The following diagram explains all the procedures

STEP 03: Find Candidate key from Minimal Super Key
Take Proper Subset of updated minimal super key which is {A,B} = {A}, {B}
- {A}+ = {A}
- {B}+ = {B}
None of the proper subsets can determine all attributes of relation R, so the minimal super key itself is a candidate key, which is {A, B}. The following diagram shows this process

STEP 04: Find Prime Attributes
{A} and {B} are prime attributes because they are part of the candidate key. The following diagram shows it

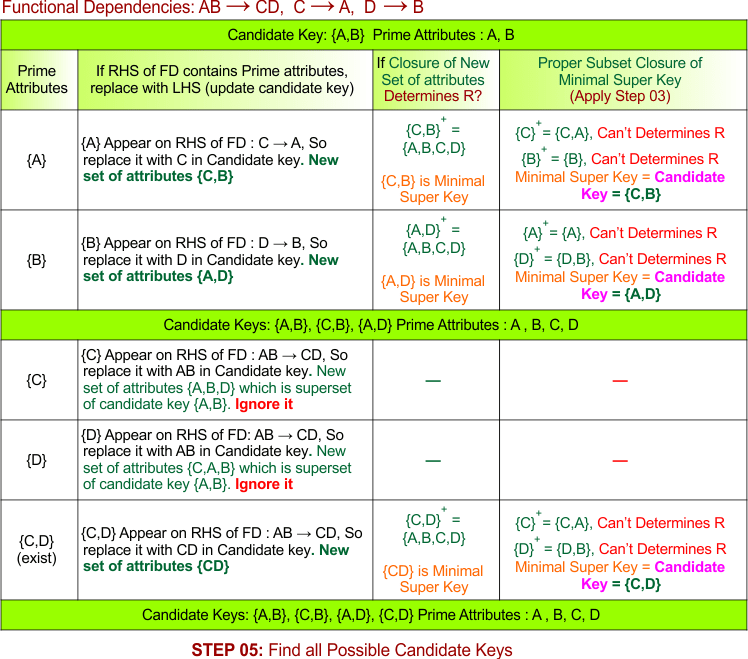
STEP 05: Find all possible Candidate Keys
STEP 6: Last Step to find some more Candidate Keys
- Only the FD (AB → CD) contains a candidate key {A,B} at LHS, and it’s RHS is already a candidate key which derived in step 05
No further candidate key is derived.
Step 07 Result:
List of candidate keys is given below
- {A,B}
- {C,B}
- {A,D}
- {C,D}
Find Candidate Keys in DBMS: Example – 8
When the relation R (A, B, C, D, E) has the following functional dependencies, then find all possible candidate keys
- AB→ CD
- D→ A
- BC → DE
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes {A, B, C, D, E}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D, E}
STEP 02: Updated Minimal Super Key
There are three functional dependencies (FD)
First FD: AB → CD
Take the RHS of First FD, which is {CD}, discard it from the initial minimal super key {A, B, C, D, E}
- {A,B,C,D,E} – {C,D} = {A,B,E}
Now find the closure of {A, B, E}
- {A,B,E}+ = {A,B,C,D,E}
{A,B, E}+ determines the entire relation {A, B, C, D}. So, the discard is successful. Now Updated minimal super key = {A,B,E}
Second FD: D → A
Take the RHS of Second FD, which is {A}, and discard it from the updated minimal super key {A, B,E}
- {A,B,E} – {A} = {B,E}
Now find the closure of {B,E}
- {B,E}+ = {B,E}
{B,E}+ does not determines the entire relation {A, B, C, D,E}. So, the discard cannot be successful. Now Updated minimal super key = {A,B,E}
Third FD: BC → DE
Take the RHS of Third FD, which is {D, E}, and discard it from the updated minimal super key {A, B}
- {A,B,E} – {D,E} = {A,B}
Now find the closure of {A, B, E}
- {A, B}+ = {A, B, C, D, E}
{A,B, E}+ determines the entire relation {A, B, C, D,E}. So, the discard is successful. Now Updated minimal super key = {A,B}
No other functional dependencies exist, so that no further attributes can be discarded. So, the final updated minimal super key = {A, B}. The following diagram explains all the procedures

STEP 03: Find Candidate key from Minimal Super Key
Take Proper Subset of updated minimal super key which is {A,B} = {A}, {B}
- {A}+ = {A}
- {B}+ = {B}
None of the proper subsets can determine all attributes of relation R, So the minimal super key itself is a candidate key, which is {A,B}. The following diagram shows this process

STEP 04: Find Prime Attributes
{A} and {B} are prime attributes because they are part of the candidate key. The following diagram shows it

STEP 05: Find all possible Candidate Keys

STEP 6: Last Step to find some more Candidate Keys
- FD (AB → CD) contains a candidate key {A, B} at LHS, and its RHS is {CD}; {CD} closure cannot determine all attributes of the relation. So, CD is not valid for the candidate key.
- FD (BC → DE) contains a candidate key {B, C} at LHS, and its RHS {DE}, {DE} closure cannot determine all attributes of the relation. So, CD is not valid for the candidate key.
No further candidate key is derived.
Step 07 Result:
The list of candidate keys is given below
- {A,B}
- {B,D}
- {C,B}
Find Candidate Keys in DBMS: Example – 9
When the relation R (W, X, Y, Z) has the following functional dependencies, then find all possible candidate keys
- Z → W
- Y → XZ
- XW → Y
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains four attributes (W, X, Y, Z). So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {W, X, Y, Z}
STEP 02: Updated Minimal Super Key

STEP 03: Find Candidate key from Minimal Super Key

STEP 04: Find Prime Attributes

STEP 05: Find all possible Candidate Keys

STEP 6: Last Step to find some more Candidate Keys
- FD (Y → XZ) contains a candidate key {Y} at LHS, and its RHS is {XZ}; {XZ} closure determines all attributes of the relation, and none of its proper subsets determines relation R. So, XZ is valid for the candidate key.
- FD (XW → Y) contains a candidate key {X, W} at LHS, and its RHS {Y}, {Y} is already a candidate key
No further candidate key is derived.
Step 07 Result:
The list of candidate keys is given below
- {Y}
- {XW}
- {ZW}
Find Candidate Keys in DBMS: Example – 10
When the relation R (A, B, C, D, E, F) has the following functional dependencies,
- Functional Dependencies: AB → C, C → DE, E → F, D → A, C → B
Let’s calculate candidate keys using the 5 steps discussed earlier
STEP 01: Initial Minimal Super Key
The relation contains six attributes {A, B, C, D, E, F}. So, the initial minimal super key contains all these attributes.
- Initial minimal super key = {A, B, C, D, E, F}
STEP 02: Updated Minimal Super Key
Initial minimal Super Key: = {A, B, C, D, E, F}. Discard the RHS attributes of functional dependencies from the initial minimal super key one by one and check whether the remaining attributes still determine the relation.
First FD: AB → C
- Discard {C} because it depends on {A, B}.
- Remaining set = {A, B, C, D, E, F} – {C} = {A, B, D, E, F}
- Its closure still determines all attributes of R, so the discard is successful.
Second FD: C → DE
- Discard {D, E} because they depend on {C}.
- Remaining set = {A, B, D, E, F} – {D, E} = {A, B, F}
- Its closure still determines all attributes of R, so the discard is successful.
Third FD: E → F
- Discard {F} because it depends on {E}.
- Remaining set = {A, B, F} – {F} = {A, B}
- Its closure still determines all attributes of R, so the discard is successful.
Fourth FD: D → A
- Discard {A} because it depends on {D}.
- Remaining set = {A, B} – {A} = {B}
- Its closure does not determine all attributes of R, so the discard is not possible.
Fifth FD: C → B
- Discard {B} because it depends on {C}.
- Remaining set = {A, B} – {B} = {A}
- Its closure does not determine all attributes of R, so the discard is not possible.
Therefore, Updated Minimal Super Key = {A, B}. Following diagram explains it

STEP 03: Find Candidate key from Updated Minimal Super Key
Take Proper Subset of updated minimal super key which is {A,B} = {A}, {B}
- {A}+ = {A}
- {B}+ = {B}
None of the proper subsets can determine all attributes of relation R, So the minimal super key itself is a candidate key, which is {A, B}. The following diagram shows this process

STEP 04: Find Prime Attributes
{A} and {D} are prime attributes because they are part of the candidate key. The following diagram shows it

STEP 05: Find all Possible Candidate Keys
As prime attributes {A} and {B} appear at the RHS of some FD’s. This will produce some more minimal super keys. Repeat steps 3 and 4 over minimal super keys, which can generate more candidate keys along with some more prime attributes as {C}, {D}. All procedures are explained in the following diagram

STEP 6: Last Step to find some more Candidate Keys
No further candidate key is derived.
Step 07 Result:
The list of candidate keys is given below
- {A,B}
- {B,D}
- {C}