
Distributed Database Architecture in DBMS
A Distributed Database Architecture in DBMS refers to a system where the database is not stored in a single location but is instead spread across multiple sites (i.e., servers or data centers). These sites are connected through a computer network (LAN, WAN, or Internet) and work together to give users the experience of accessing a single unified database.
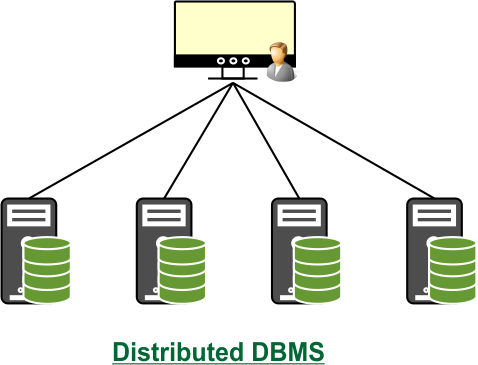
- This architecture is widely used in banking, e-commerce, cloud platforms, and social media because it provides better performance, high availability, scalability, and fault tolerance compared to a centralized system.
- By dividing and replicating data across sites, a distributed database ensures that even if one site fails, the system as a whole continues to work smoothly.
Before proceeding to this lecture, you must know the term “site”
Site in a Distributed DBMSIn a distributed DBMS, the word “site” does not mean a website.
ExampleIn a banking system:
In Google Cloud Spanner:
|
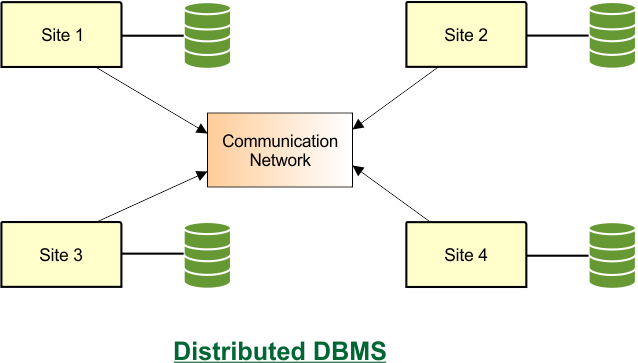
How Sites Work Together in Distributed DBMS
In a Distributed DBMS (DDBMS), the database is stored at different sites (servers or data centers). Even though the data is spread out, all sites work together like a single system for the user. Let me explain the main components of its mechanism.
1. Data Fragmentation
In a distributed DBMS, data is not stored in one central location. Instead, it is spread across multiple sites to improve speed, reliability, and availability. The database is divided into smaller fragments (horizontal or vertical). Each site stores only the relevant portion of data needed for its users.
Example: If a person has a business selling products in London, New York, and Singapore, then:
- The Singapore site keeps records of Asian customers.
- The New York site keeps records of US customers.
- The London site keeps records of European customers.
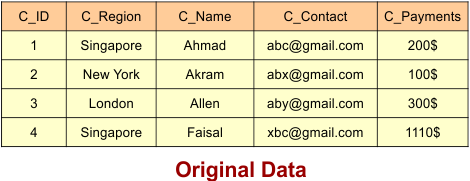
Let’s explain both types of fragmentation: horizontal and vertical, with an example. Consider the following original data belonging to a company.
a). Horizontal Fragmentation
The table (relation) is divided row-wise. Each fragment contains a subset of rows based on some condition. All fragments have the same columns (attributes), but different rows. Useful when different sites handle data for different regions/customers.
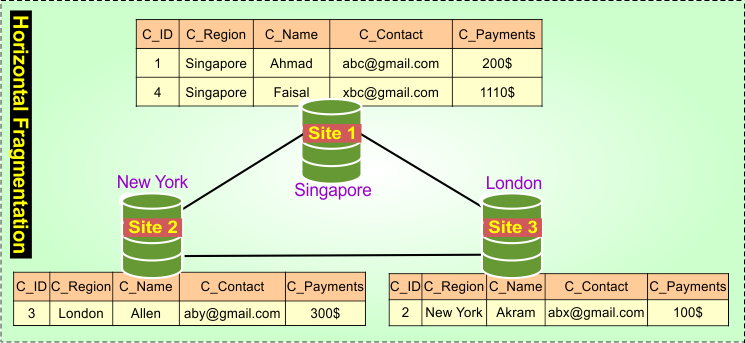
Example: A Customer table is split by region
- Singapore site 1 contains rows: Asian customers
- New York site 2 contains rows: US customers
- London site 3 contains rows: European customers
Each site stores only its local customers, reducing access time.
b) Vertical Fragmentation
The table is divided column-wise. Each fragment contains a subset of attributes (columns). All fragments must include the primary key to allow reconstruction of the full table. Useful when different sites need only specific attributes.
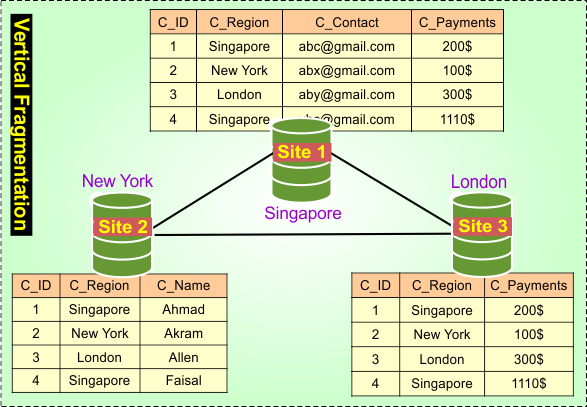
Example: A Customer table where C_ID is a primary key, and it is split into the following
- Singapore site 1 contains columns: C_ID, C_Region, C_Contact, C_payments
- New York site 2 contains columns: C_ID, C_Region, C_Contact
- London site 3 contains columns: C_ID, C_Region, C_payments
Each site stores only the data it needs most.
2. Local Processing
In a distributed DBMS, every site has its own DBMS software to manage the data stored locally. This allows each site to process local queries independently, without needing help from other sites.
Example: If a customer in New York checks their account balance, the request is handled only by the New York site, since the customer’s data is already stored there. No need to contact London or Singapore, so it’s faster.
3. Global Queries
A global query is a query that needs data from many sites (not just one). The distributed DBMS will:
- Break the query into smaller parts.
- Send each part to the site that has the required data.
- Collect all answers from those sites.
- Join them together and give the final result to the user.
Here is the descriptive diagram for global queries
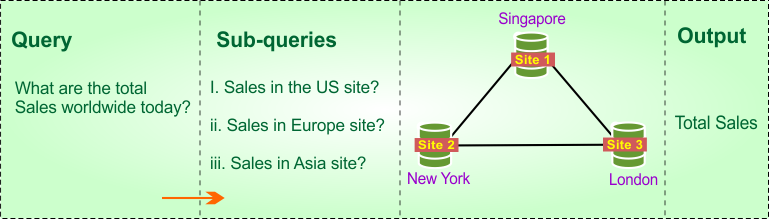
In the above diagram the Amazon wants to know: “What are the total sales worldwide today?”. The distributed DBMS will:
- Ask the US site for sales in the US.
- Ask the Europe site for sales in Europe.
- Ask the Asia site for sales in Asia.
Then, it adds them all up and shows one final total report.
4. Replication & Synchronization
In a Distributed DBMS, some data is copied and stored in more than one site. This is called replication. Replication increases safety and availability. if one site goes down, the same data is still available at another site.
When data is updated at one site, the DDBMS makes sure that the same update is copied to all other sites. This process is called synchronization.
Example: A company keeps its customer database in New York, London, and Singapore.
- This means each site has a copy of customer records (replication).
- If the London site updates a customer’s phone number, the same update is automatically reflected at the New York and Singapore sites. So no matter which site you use, you always see the latest correct data.
5. Communication Between Sites
Sites communicate through a network (LAN, WAN, or Internet) to share data and updates.
Example: When a European customer orders a product stored in the US warehouse, the European site communicates with the US site to process and confirm the order.
Types of Distributed DBMS
Distributed DBMS is mainly of two types:
i. Homogeneous Distributed DBMS
In a homogeneous DDBMS, all the sites (computers/servers) use the same DBMS software and follow the same data model. The databases look and behave in a uniform way across all sites.
Example: If all sites are using Oracle DBMS or all are using MySQL.
Key Points:
- It requires the same DBMS software across all sites. While having the same operating system and hardware is common for easier integration, it is not a strict requirement.
- Easy query processing because rules are identical.
- It is easier to manage, integrate, and maintain consistency.
- Best suited when all locations belong to the same organization.
ii. Heterogeneous Distributed DBMS
In a heterogeneous DDBMS, different sites may use different DBMS software (e.g., Oracle at one site, MySQL at another, SQL Server at another). The system must translate queries and data formats so that users can still access data as if it were a single database.
Key Points:
- Different DBMS software at different sites.
- May also have different hardware and operating systems.
- Requires extra software (middleware) to handle communication and translation.
- It is more complex to manage but also more flexible, as organizations can use existing databases without changing them.
- Best suited for large organizations, mergers, or collaborations where different systems must work together.
|
Imagine a bank:
|
Advantages of Distributed DBMS
Advantages of Distributed Database Management Systems (DBMS) are given below
i. Improved Reliability & Availability
If one site (server or data center) fails, the other sites continue working. This ensures uninterrupted access to data and services.
-
Example: If the London site goes down, users in New York and Singapore can still access their data.
ii. Better Performance
Data is stored closer to where users are located, which means faster query response and less network delay.
-
Example: A customer in Singapore accessing product info will get results from the Singapore site instead of waiting for data from New York.
iii. High Scalability
New servers or sites can be added without disturbing the existing system. This makes it easier to expand as the business grows.
-
Example: If a company starts operations in Dubai, a new database site can be added and connected to the system.
iv. Local Autonomy
Each site manages and controls its own database independently. This gives flexibility while still being part of the global system.
-
Example: The New York site can update its local sales data without needing approval from London or Singapore.
v. Reduced Communication Cost
Queries are processed locally whenever possible, so there’s no need to transfer large amounts of data over the network.
-
Example: A local London customer order is handled at the London site without involving other sites.
vi. Fault Tolerance
Data is often replicated across multiple sites, so if one copy is lost, another is available.
- Example: If the Singapore site crashes, the system can use data copies from New York or London.
Disadvantages of Distributed DBMS
While Distributed DBMS offers many benefits, it also comes with challenges, which are given below
i. Complex Design
Managing databases across different sites is much harder than handling a single centralized system. It requires careful planning for data distribution, replication, and synchronization.
-
Example: A company with sites in London, New York, and Singapore must ensure that customer data is properly divided and kept consistent across all three locations.
ii. High Implementation Cost
Setting up a Distributed DBMS needs advanced hardware, high-speed networks, and skilled professionals. This makes it expensive to install and maintain, especially for small businesses.
-
Example: A small retail chain may find it too costly to set up servers in multiple countries and hire experts to manage the distributed system.
iii. Security Challenges
Since data is spread across multiple sites, ensuring data privacy and protection is more difficult. Each site must implement strong security policies, which increases complexity.
-
Example: If the New York site is hacked, attackers might gain access to sensitive customer data even if other sites are secure.
iv. Data Integrity Issues
When the same data is stored at different sites (replication), keeping it consistent during updates is difficult. Even a small delay in synchronization can cause conflicting or outdated data.
-
Example: If the London site updates product prices but the Singapore site has not yet received the update, customers may see different prices.
v. Slower Global Queries
If a query requires data from multiple sites, the system must communicate across the network. This increases response time compared to a centralized database.
-
Example: If the head office requests a global sales report, the system must collect data from London, New York, and Singapore, which takes longer.
vi. Difficult Maintenance
Tasks like troubleshooting, upgrades, or backups are more complicated in a distributed system. Administrators must ensure that all sites are properly updated and running smoothly.
-
Example: If the DBMS software is updated, the update must be applied to all sites (London, New York, Singapore). If one site fails to update, it may cause errors.
Examples of Distributed DBMS
Examples of Distributed Database Management Systems (DBMS) are
i. Google Spanner
A cloud-based, globally distributed relational database developed by Google. It provides high availability, scalability, and strong consistency across multiple continents.
-
Example Use Case: Google uses Spanner to manage services like Gmail, Google Ads, and Google Photos, where data from millions of users worldwide must remain consistent.
ii. Amazon DynamoDB
A fully managed NoSQL distributed database offered by Amazon Web Services (AWS). Known for low latency and automatic scaling, making it ideal for high-traffic applications.
-
Example Use Case: DynamoDB powers e-commerce platforms, mobile apps, and gaming systems like Amazon.com and Fortnite, ensuring fast response times even during heavy user load.
iii. Oracle RAC (Real Application Clusters)
An enterprise-level distributed DBMS that allows multiple servers to run Oracle databases simultaneously. Provides high availability and load balancing by allowing multiple nodes to access the same database.
-
Example Use Case: Large banks and telecom companies use Oracle RAC to handle millions of transactions per second without downtime.
iv. Apache Cassandra
A highly scalable NoSQL distributed DBMS designed for handling massive volumes of data across many servers with no single point of failure.
-
Example Use Case: Companies like Netflix, Facebook, and Twitter use Cassandra to store and retrieve user activity, recommendations, and messages.
v. MongoDB (Sharded Cluster Setup)
A popular document-oriented distributed NoSQL database that uses sharding to distribute data across multiple servers. Provides flexibility for applications that deal with unstructured or semi-structured data.
-
Example Use Case: Businesses like Uber, eBay, and Adobe use MongoDB to handle large-scale data from users across the globe.
Applications of Distributed DBMS
Applications of Distributed DBMS are widely used in banking, e-commerce, social media, and cloud platforms to manage data across multiple sites. It ensures fast access, high reliability, and scalable database management for modern businesses.
i. Banking Systems
Banks have branches in multiple cities or countries. Each branch maintains its own database but is connected to the central system through a Distributed DBMS.
-
Example: If a customer opens an account in Karachi, they can withdraw money in Lahore or London, because all branch databases remain synchronized in real time.
ii. E-commerce Platforms
Online shopping giants handle millions of users and transactions daily. Distributed DBMS helps them store customer data, product catalogs, and order details at different locations to reduce response time.
-
Example: Amazon, Flipkart, and Daraz store user and product data in regional data centers (US, Europe, Asia) so customers experience fast browsing and checkout.
iii. Social Media Platforms
Social media apps generate massive amounts of user posts, likes, comments, and messages every second. A Distributed DBMS ensures this data is stored across multiple servers globally to handle high traffic.
-
Example: Facebook, Instagram, and Twitter (X) keep user data in distributed clusters worldwide, so users can access their accounts quickly from any country.
iv. Cloud Databases
Cloud service providers offer Distributed DBMS as a service to businesses. These systems ensure scalability, high availability, and automatic backups without needing in-house servers.
-
Example: AWS DynamoDB, Google Cloud Spanner, and Microsoft Azure Cosmos DB are widely used for apps, SaaS platforms, and global enterprises.
Difference Between Centralized and Distributed DBMS
A Centralized DBMS stores all the data in one single location, usually on a central server. In contrast, a Distributed DBMS spreads the database across multiple sites or servers connected through a network, but it appears as a single unified system to the user.
Here are the main differences in table between Centralized and Distributed DBMS
| Feature | Centralized DBMS | Distributed DBMS |
|---|---|---|
| Storage | All data is stored in a single central server. | Data is stored across multiple sites/servers connected by a network. |
| Performance | Slows down as the number of users increases, since all requests go to one server. | Faster response time as data is located closer to users and workload is shared across sites. |
| Failure | Single point of failure – if the central server goes down, the whole system stops. | More reliable – if one site fails, other sites can still operate. |
| Security | Easier to manage since only one server needs security policies. | More complex because security must be managed at multiple sites. |
| Scalability | Difficult to expand – adding more users or data can overload the system. | Highly scalable – new sites/servers can be added easily without disrupting the system. |
| Cost | Lower cost to set up and maintain since it requires only one server. | Higher cost due to multiple servers, networking, and skilled staff. |
| Data Access | Suitable for small organizations with limited data access needs. | Suitable for large, global organizations requiring fast and reliable access from multiple locations. |
Conclusion
A Distributed DBMS is the backbone of modern large-scale applications, providing high availability, fault tolerance, and performance. While it is more complex and costly than a centralized DBMS, it is essential for organizations dealing with big data, global services, and cloud computing.
In simple words, a Distributed DBMS = Multiple databases working together as one big database.