










Pipelining And Non-Pipelining
There are two common methods used to process the instructions. One is pipelining, and the other is non-pipeline. However, the concept of non-pipelining is replaced with pipelining due to its lower efficiency and throughput. Let’s explain both terms
1. Non-pipelining
In a non-pipelining concept, each instruction is passed through some stages, which are given below to complete its execution.
- Fetch
- Decode
- Execute
- Memory
- Write back
The second instruction has to wait until the first instruction is completed.
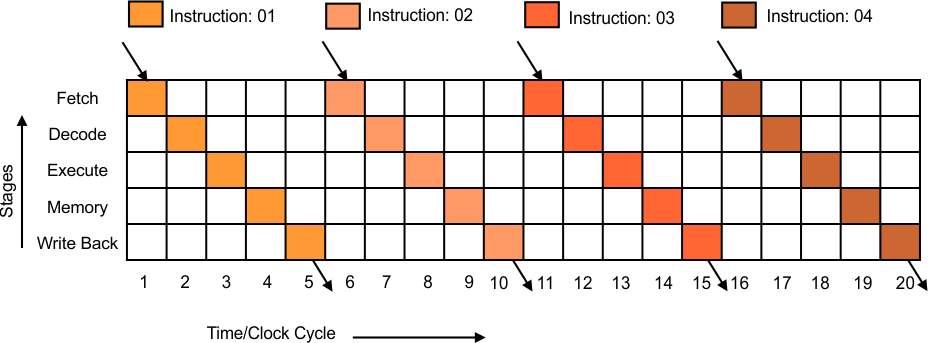
So, each instruction passes through five stages. Each stage is completed in one clock cycle. So, 4 instructions will take 20 clock cycles to complete in non-pipelining.
Numerical problems on non-pipelining
Q1: If 15 milliseconds are given to each clock cycle, and 4 instructions pass through 5 stages to complete its execution in a non-pipeline,
- How much time is required to complete the execution of all instructions?
- Calculate the efficiency of the system
Solution: A
- Total clock cycle= K*N ( as K are stages, so k=5 and N are no of instructions, so n=4)
- =5*4
- =20
- Time for one clock cycle 15 ms
- Time for 20 clock cycles = 15*20 ms
Solution: B
- Efficiency or utilization = total no of used box in no-pipelining/ Total no of boxes.
- In 4 instructions diagram with 5 stages total box are 80.
- 4 instuctions each use 5 stages, so total 20 boxe are used
- Efficieny or utilization = 20/80= ¼.
2. Pipelining
Execution of more than one overlap instruction is called pipelining. In this way, CPU performance increased. In a pipelining concept, each instruction is also passed through five stages to complete as
- Fetch
- Decode
- Execute
- Memory
- Write back
But the 2nd instruction starts execution when the first instruction is at the decoding stage. 3rd instruction starts execution when 2nd instruction is a decoding stage, and so on.
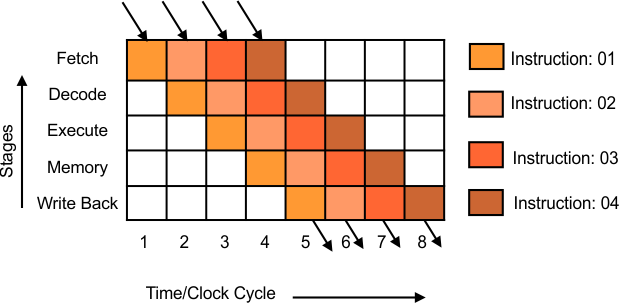
In this way, 4 instructions were completed in just 8 clock cycles, while in non-pipelining, it was 20.
Need of Pipelining
Purpose: CPI (clock per instruction) is equal or equivalent to ONE. The higher the no of instructions, the higher the probability of achieving the CPI target (which is one)
Note: only the first instruction takes 5 clock cycles to complete. Other instructions are completed in one clock cycle. So, the first instruction execution clock cycle (time period) equals the number of stages, and all further instructions are executed in one clock cycle.
Note: One clock cycle is sometimes in which instruction is executed
When a clock cycle is applied in pipelining, then all stages (fetch, decode, execute, memory, write back) of processing are executed. But at a time, only one stage is executed for one instruction. This means that instruction-1 cannot fetch and decode at the same time. But instruction-1 can fetch, and instruction-2 can decode at the same time.
Numerical problems with pipelining
Q1: If 15 milliseconds are given to each clock cycle, and there are 4 instructions that pass through 5 stages to complete its execution in the pipeline,
- How much time is required to complete the execution of all instructions?
- Calculate the efficiency of the system
Solution: A
- Total clock cycle= K+ (n-1) as k are stages so k=5 and n are no of instructions so n=4
- =5+(4-1)
- =8
- Time for one clock cycle 15 ms
- Time for 8 clock cycles = 15*8 ms
Solution: B
- Efficiency or utilization = total no of used boxes in pipelining/ Total no of boxes
- In 4 instructions diagram with 5 stages, the total box boxes is 40.
- 8 instructions, each using 5 stages, so a total of 20 boxes are used
- Efficiency or utilization = 20/40= ½
Conclusion : CPI is almost one in pipelining and has higher efficiency and throughput in the pipeline as compared to non-pipelining.
Essential points about Pipelining and non-pipelining
SpeedUp Formula
The ratio between non-pipelining and pipeline is speed up. 8 instructions were completed in 12 clock cycles in the pipeline, but 40 cycles were required for non-pipelining. So Speedup will be
Speedup = NP/P = 40/12 =3.1, so 3.1 times is Speedup. NP is non-pipelining, and P is pipelining.
Stage Delay
Every stage has circuits that are used to process data. So, some time is required at every stage, called stage delay.
Registers Delay
Registers between stages are used to store intermediate results. These registers store the input value from the previous stage for the very next stage. If the stage delay is uniform, then we have no delay in registers. We can directly pass it to the next stage.
But if one stage’s processing speed is mismatched with another stage (means to say stage 1 is complete in 5ns but stage 2 is still in processing or its delay time is 8ns), then we have to store intermediate results in registers for some time to complete the next stage (stage 2).
Stages delay, and registers delay are given below in the diagram,

Numerical Problems
Question 1: A 4-stage pipeline has stage delays as 150,120, 160, and 140ns. Registers are used between stages and have a delay of 5ns each. Assuming a constant clock rate, the total time taken to process 1000 data items on this pipeline will be—-?
Solution:
Consider a maximum stage delay so that the other instructions may executed, it founds in stage 3 which is equal to 165 (160-stage delay+5-register delay).
First, instruction/data passes through the entire stage, and the rest of the instructions will follow the pipeline. Every instruction is complete in every stage. So, the formula will be as follows.
First instruction x stages x time + Rest instructions x stages x time
= 1x4x165 + 999 x 1 x 165 ns = 165.5 usec.
Question No 02: Consider a non-pipelined processor with a clock rate of 2.5 GHz and an. Cycle/instructions of four. The same processor is upgraded to a pipelined processor with five stages. However, the clock speed is reduced to 2 GHz due to internal pipeline delay. Assume that there is no stall (ideal condition) in the pipeline. The Speedup achieved in the pipeline processor is?
- Speedup = TNP/TP (“NP” is non-pipelining and “P” is pipelining)
- As T= 1/F = So,
- TNP = 4×1/2.5×109 Sec
- Tp = 1x 1/2×109 Sec
- Speedup = (4×1/2.5×109 Sec) / (1x 1/2×109 Sec)
Note: Time for one instruction = cycles per instruction x clock rate